随着LLM业务的不断发展,我们发现单机单卡无法承载一个模型的训练和推理,故此出现了单机多卡和多机多卡的训练推理算子,这时候每个机和卡之间都需要通信,所以通信算子十分的重要。
下面是传统的四种并行处理架构,常用于大模型训练。


每张卡拷贝相同的模型结构,仅对数据做切分。每张卡计算完的梯度也是针对各自数据的,需要做一次allreduce,然后使用优化器更新模型,进入下一次迭代。
限制场景:模型必须要放得进一张卡里
这里算子需要做的是 All Reduce 和 Broadcast
数据大,也有可能是模型大,张量并行是指对模型内部的参数矩阵切分,然后利用分块矩阵乘进行计算得到正确结果,由于参数矩阵是以tensor表示,故叫张量并行
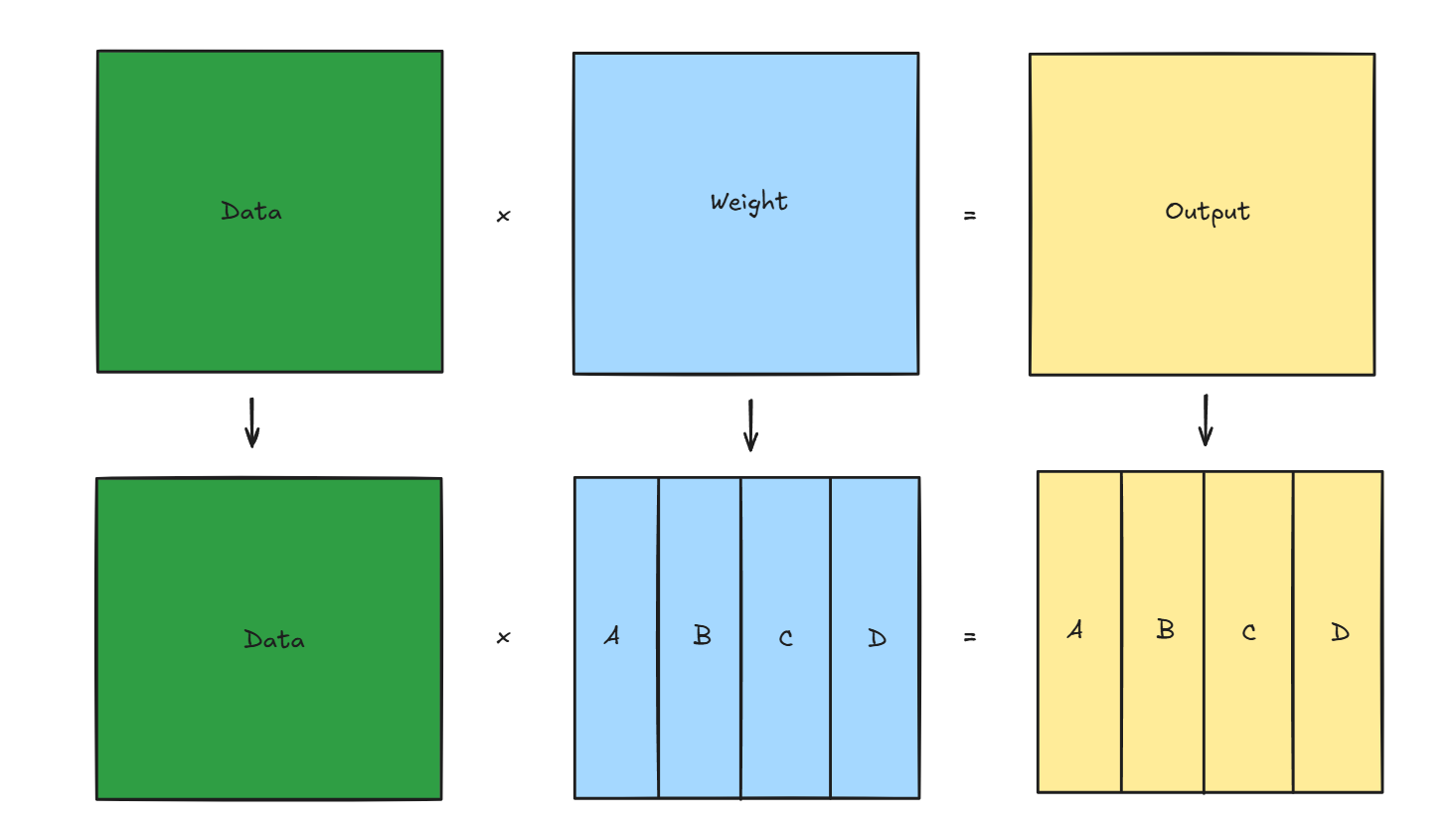
如下图,每个模块会放在不同的GPU里,由于每个模块的运算量,大小,通信速率都不一样

张量并行的优点是能分摊模型到多张卡上,缺点是带来了不小的通信开销,影响训练效率
算子需要做的事情是All Reduce、AllGather、Reduce Scatter
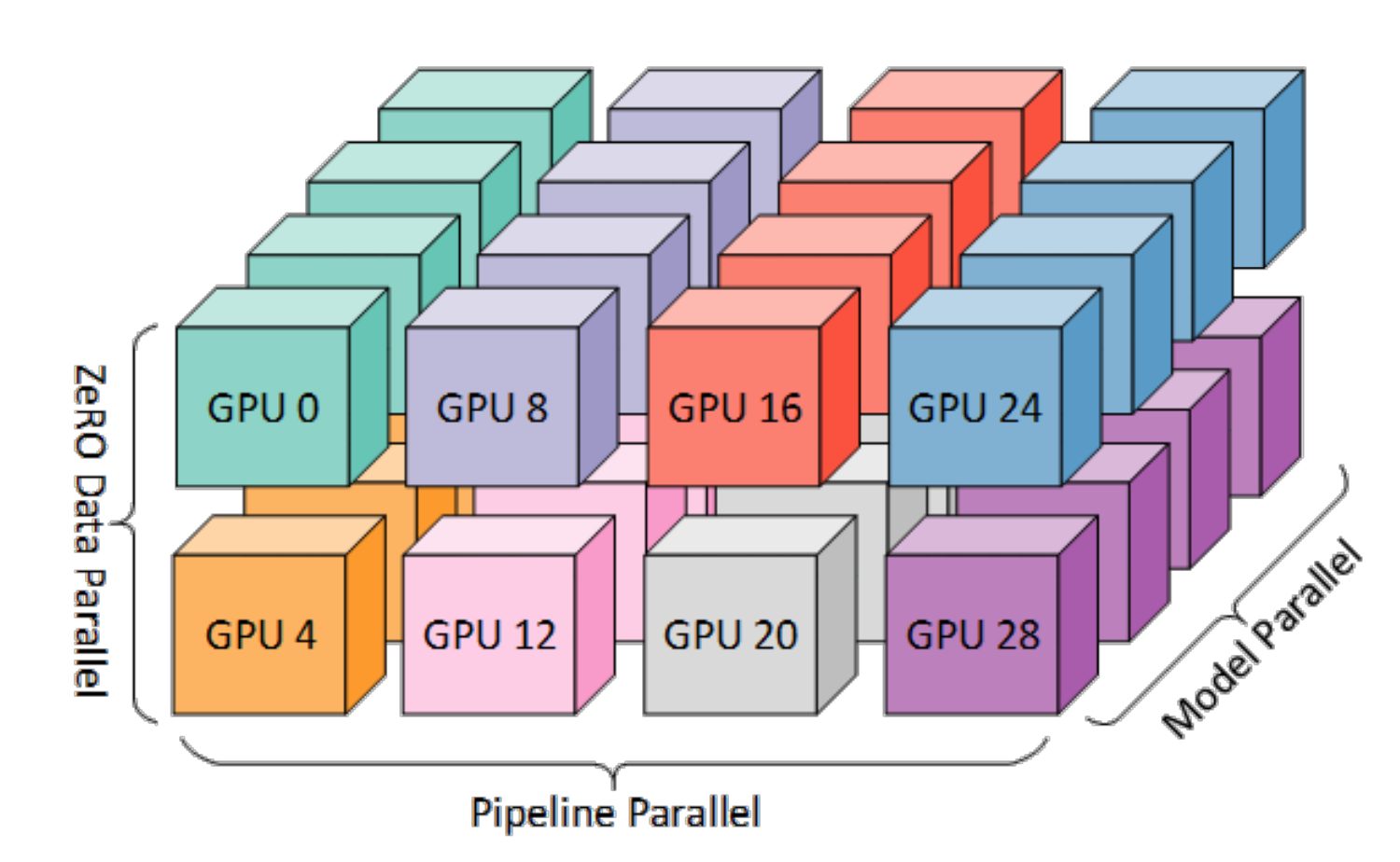
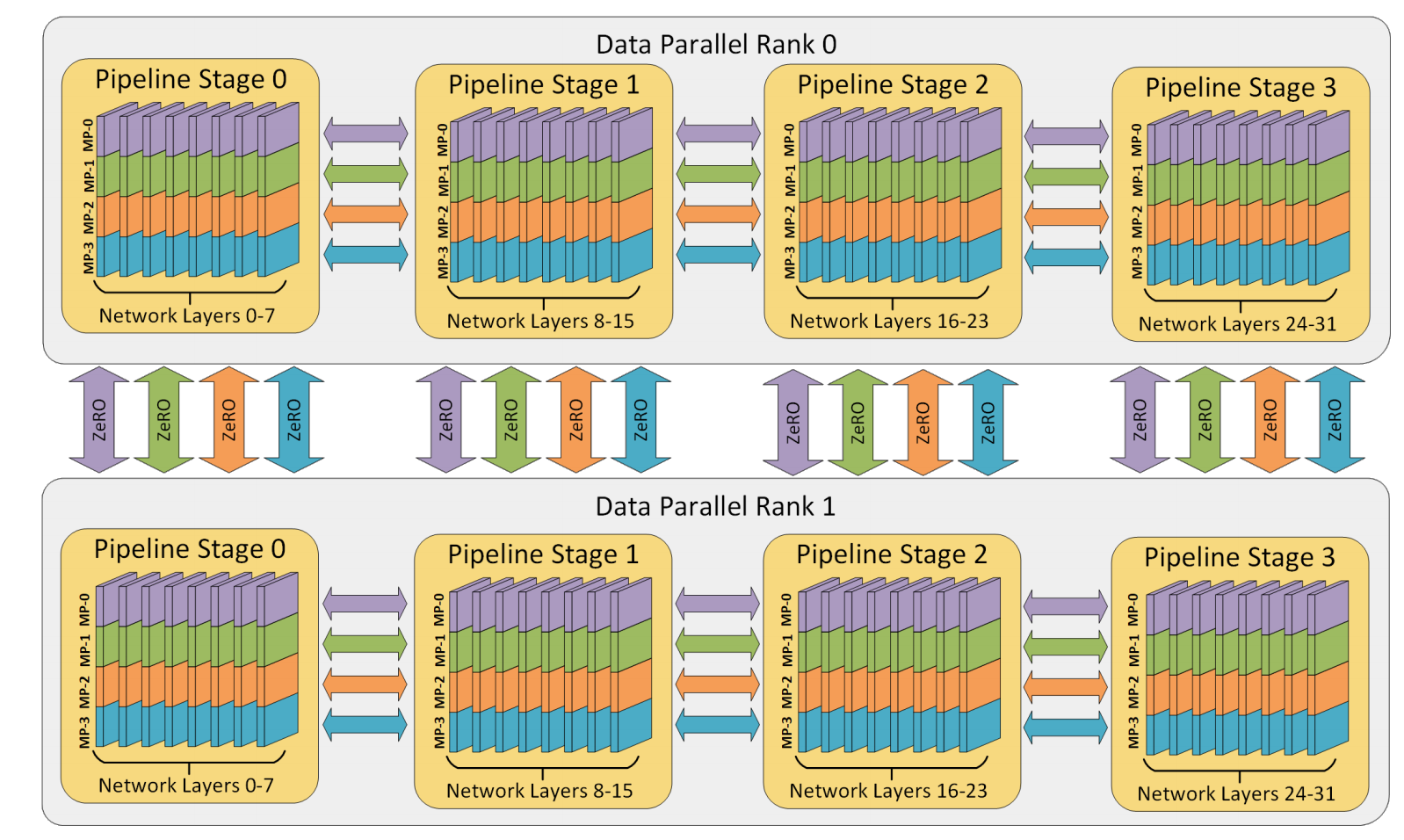
上面说的张量并行是对矩阵进行切分,缺点是通信量很大。另一种思路是按layer进行切分,例如一个模型是80层,切分到8张卡上,每一张卡放10层。

上图中每一个小方块就是一个micro-batch,可以看到随着时间的发展很多设备存在气泡
(记得把优化写完)
算子要做的是Send、Recv
算子要做的是All Reduce、AllGather、Reduce Scatter
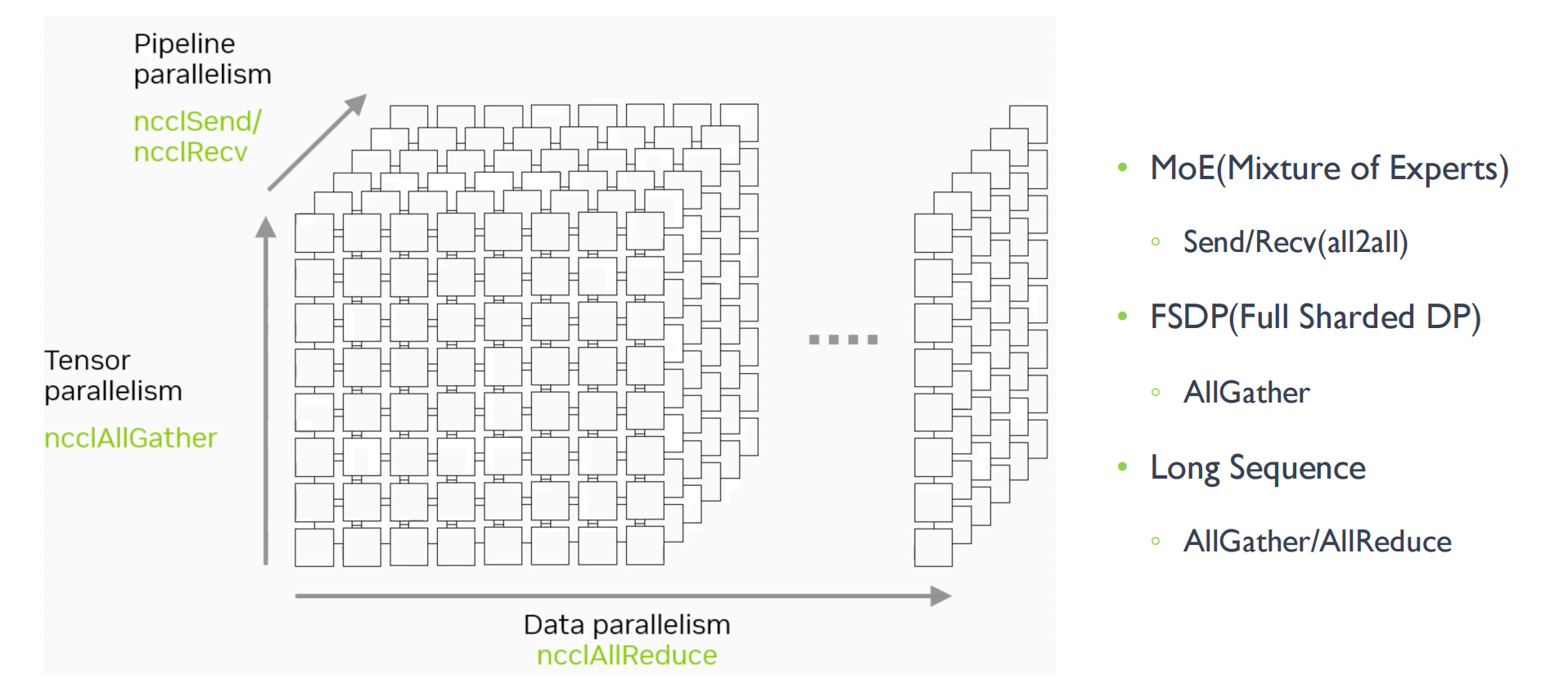
专家并行主要解决的是MoE模型的问题,根据路由转发之后token发给某个指定的专家,但是由于节点往往不能接受全部的token,所以这里会做一层DP,进行数据的切分。
算子要做的是All2All的算子
高效all2all最核心的矛盾点就是 incast 和 stragglers,都是会导致拥塞,结果就是导致排队延迟、数据包丢失和链路利用率低下。
incast:当多个网络流指向同一接收者时会发生incast
stragglers:某些传输完成时间显著长于同时调度的其他成对传输。在等待这些“stragglers”传输完成之前不允许新的成对传输开始,会导致大部分网络处于空闲状态,造成传输的bubble
解决方法就是设计调度器,使得同一时间一个对象只有一个流进行数据传输。然后对于stragglers传输的时候尽可能的消除bubble。
在16机8卡的场景中,直接的 Alltoall 全连接 每个 rank 需要 127 个 P2P 连接,这带来了相当多的通信开销:
首先把一个节点发给另一个节点的数据全部打包,一起发过去
另一个节点收到了之后将数据解包,然后把另一个节点需要的数据发过去
这样的优化带来的效果就是一个节点只需要22个P2P连接(1个节点和另外7个节点之间的连接,节点内的一个卡和另外15个卡的通信)
由于这里存在相当的一对一通信,为了避免多个节点卡在向同一个节点发送数据带来的Incast 问题,需要采用了分阶段、分组通信的进一步优化。
这里具体可以看paper里的FLASH
参考文献:
哈密瓜——大模型训练并行技术理解-DP/TP/PP/SP/EP
paper——ZERO BUBBLE PIPELINE PARALLELISM
paper——Reducing Activation Recomputation in Large Transformer Models
paper——Switch Transformers: Scaling to Trillion Parameter Modelswith Simple and Efficient Sparsity
