(施工ing)
我们知道,算子的作用是计算,那在整个体系中,我们的核心目标是拉满GPU的利用率。
在现代分布式体系中,多GPU之间同时存在着计算、内存访问和通信这三种基本活动,为了服务于我们的核心目标,我们需要尽可能的将通信时间和访存时间放在计算时间内,使得GPU不存在运算时间的泡泡。
大模型分布式系统执行的核心组件是并行的GPU。提升GPU运算的最佳方法,是通过计算与通信的重叠来实现。这种重叠可以通过两种方式达成:算子分解或通信内核融合。虽然算子分解实现起来简单,但往往导致性能欠佳。而将通信内核与计算内核融合,则需要更多的思考和计算。
故此最原始的想法就是用计算时间掩盖通信时间,通过大批量的数据直接发送到GPU,减少kernel开启和关闭、通信的开销。

Triton-distributed是字节seed团队开发的Triton 编译器的扩展。对于 LLM 来说,分布式优化的关键要求是计算通信重叠。以前,在小规模分布式训练/推理中,通信开销并不是一个关键的成本问题。然而,随着集群数量呈指数级增长,计算与通信重叠变得至关重要。
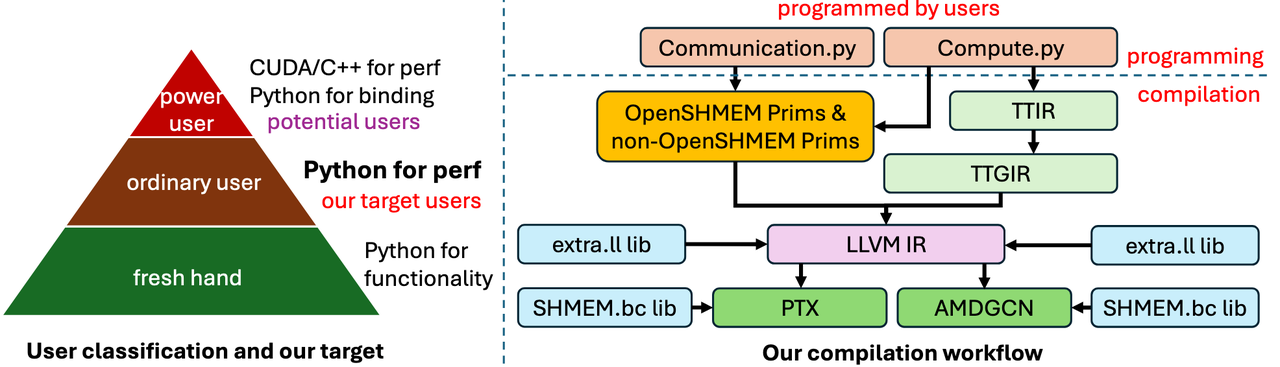
Triton-Distributed编译器技术栈
Triton-Distributed 编程模型遵循 MPMD(multiple programs multiple data)模型。其模型核心就是异步的处理信号和数据,关键技术有三个:symmetric memory 对称内存,signal exchange 信号交换,和async-task 异步任务。

symmetric memory 对称内存:每个 rank 在全局范围内分配一个相同大小的内存缓冲区。每个内存缓冲区具有独立的地址空间,没有通一的虚拟地址空间,访问只靠通信原语。
signal exchange 信号交换:每个 rank 上的操作以一致的方式通过信号相互通信。有一组固定的信号操作,包括设置信号值、增加信号值、检查信号值以及对给定信号进行自旋锁。
async-task 异步任务:所有操作都是异步的,即使在同一 rank 上,操作也是异步的。
Triton-distributed 提供了一套易于使用的原语,用于支持开发计算-通信融合的分布式kernel。这些原语分为低层次原语和高层次原语。目前,seed已经发布了低层次原语,并计划在未来发布高层次原语。代码位于Triton-distributed/python/triton_dist/language/ 。
用于通信的低级原语有:
1、Context Querying Primitives 上下文查询原语
rank(axis=-1, _builder=None)
num_ranks(axis=-1, _builder=None)
symm_at(ptr, rank, _builder=None)2、Signal Control Primitives 信号控制原语
wait(barrierPtrs, numBarriers, scope: str, semantic: str, _builder=None)
consume_token(value, token, _builder=None)
notify(ptr, rank, signal=1, sig_op="set", comm_scope="inter_node", _builder=None)3、NVSHMEM-related Primitives NVSHMEM 相关原语
除了原语之外,Triton-distributed 还将所有 nvidia shared memory 通信原语公开给 Python,允许用户纯粹用 Python 编写通信内核。位于triton.language.extra.libshmem_device 。
my_pe()
n_pes()
int_p(dest, value, pe)
remote_ptr(local_ptr, pe)
barrier_all()
barrier_all_block()
barrier_all_warp()
sync_all()
sync_all_block()
sync_all_warp()
quiet()
fence()
getmem_nbi_block(dest, source, bytes, pe)
getmem_block(dest, source, bytes, pe)
getmem_nbi_warp(dest, source, bytes, pe)
getmem_warp(dest, source, bytes, pe)
getmem_nbi(dest, source, bytes, pe)
getmem(dest, source, bytes, pe)
putmem_block(dest, source, bytes, pe)
putmem_nbi_block(dest, source, bytes, pe)
putmem_warp(dest, source, bytes, pe)
putmem_nbi_warp(dest, source, bytes, pe)
putmem(dest, source, bytes, pe)
putmem_nbi(dest, source, bytes, pe)
putmem_signal_nbi(dest, source, bytes, sig_addr, signal, sig_op, pe)
putmem_signal(dest, source, bytes, sig_addr, signal, sig_op, pe)
putmem_signal_nbi_block(dest, source, bytes, sig_addr, signal, sig_op, pe)
putmem_signal_block(dest, source, bytes, sig_addr, signal, sig_op, pe)
putmem_signal_nbi_warp(dest, source, bytes, sig_addr, signal, sig_op, pe)
putmem_signal_warp(dest, source, bytes, sig_addr, signal, sig_op, pe)
signal_op(sig_addr, signal, sig_op, pe)
signal_wait_until(sig_addr, cmp_, cmp_val)参考文献:
