主页:https://multica.ai/
github link:https://github.com/multica-ai/multica
一图胜千言,这个项目是多agent的管理项目:
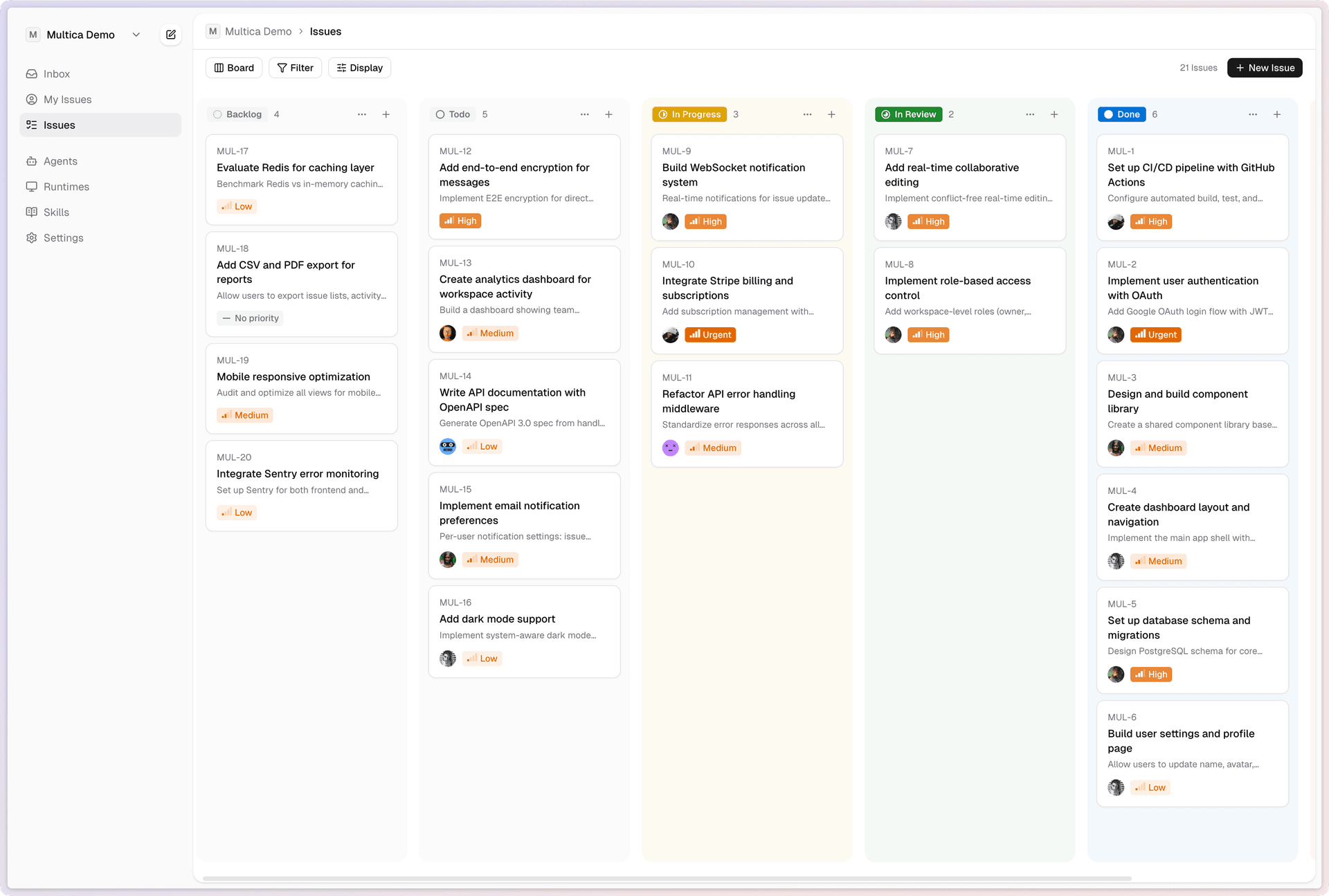
我最关心三件事:
多agent的harness
task的生命周期是如何运作的

每次任务即将执行时实时生成生成的 CLAUDE.md,是一份动态适配的检索说明书:buildMetaSkillContent()(server/internal/daemon/execenv/runtime_config.go)
生成的 CLAUDE.md 结构:
├─ Agent Identity ← 来自 agent.instructions (数据库字段)
├─ Available Commands ← 硬编码的 CLI 命令参考 (所有 Agent 通用)
├─ Repositories ← 来自 workspace.repos (数据库 JSONB 字段)
├─ Workflow ← 根据 trigger 类型动态选择:
│ ├─ assignment → 完整工作流 (status 管理 + 代码实现 + PR)
│ ├─ comment → 只读 + 回复工作流
│ └─ chat → 交互式模式
├─ Skills ← 来自 agent_skill join 查询
└─ Output Guidelines ← 硬编码的输出准则这份claude.md是在task执行之前生成的:
pollLoop() // daemon.go:684 — daemon 主循环
└─ handleTask() // daemon.go:771 — 拿到一个任务
└─ runTask() // daemon.go:875 — 准备执行
├─ execenv.Prepare() // execenv.go:68 — 创建隔离目录
├─ InjectRuntimeConfig() // daemon.go:924 — ★ 这里生成 CLAUDE.md
│ └─ buildMetaSkillContent() // runtime_config.go:33
└─ backend.Execute() // daemon.go:979 — 启动 Agent CLI在构建claude.md之前就会动态的组装上下文:(daemon.go)
// runTask() 中组装动态上下文
taskCtx := execenv.TaskContextForEnv{
IssueID: task.IssueID,
TriggerCommentID: task.TriggerCommentID, // ← 决定走哪套 workflow
AgentInstructions: instructions, // ← 来自 agent 表当前值
AgentSkills: convertSkillsForEnv(skills), // ← 来自 agent_skill join
Repos: convertReposForEnv(task.Repos), // ← 来自 workspace.repos
ChatSessionID: task.ChatSessionID, // ← 决定是否 chat 模式
}
// 每次执行都重新生成
execenv.InjectRuntimeConfig(env.WorkDir, provider, taskCtx)Context Engineering 写的 CLAUDE.md 告诉 Agent "你可以用 multica issue get 来读issue"。但这只是"说明书"——好比给了你一张超市会员卡的使用指南,却没给你卡本身。
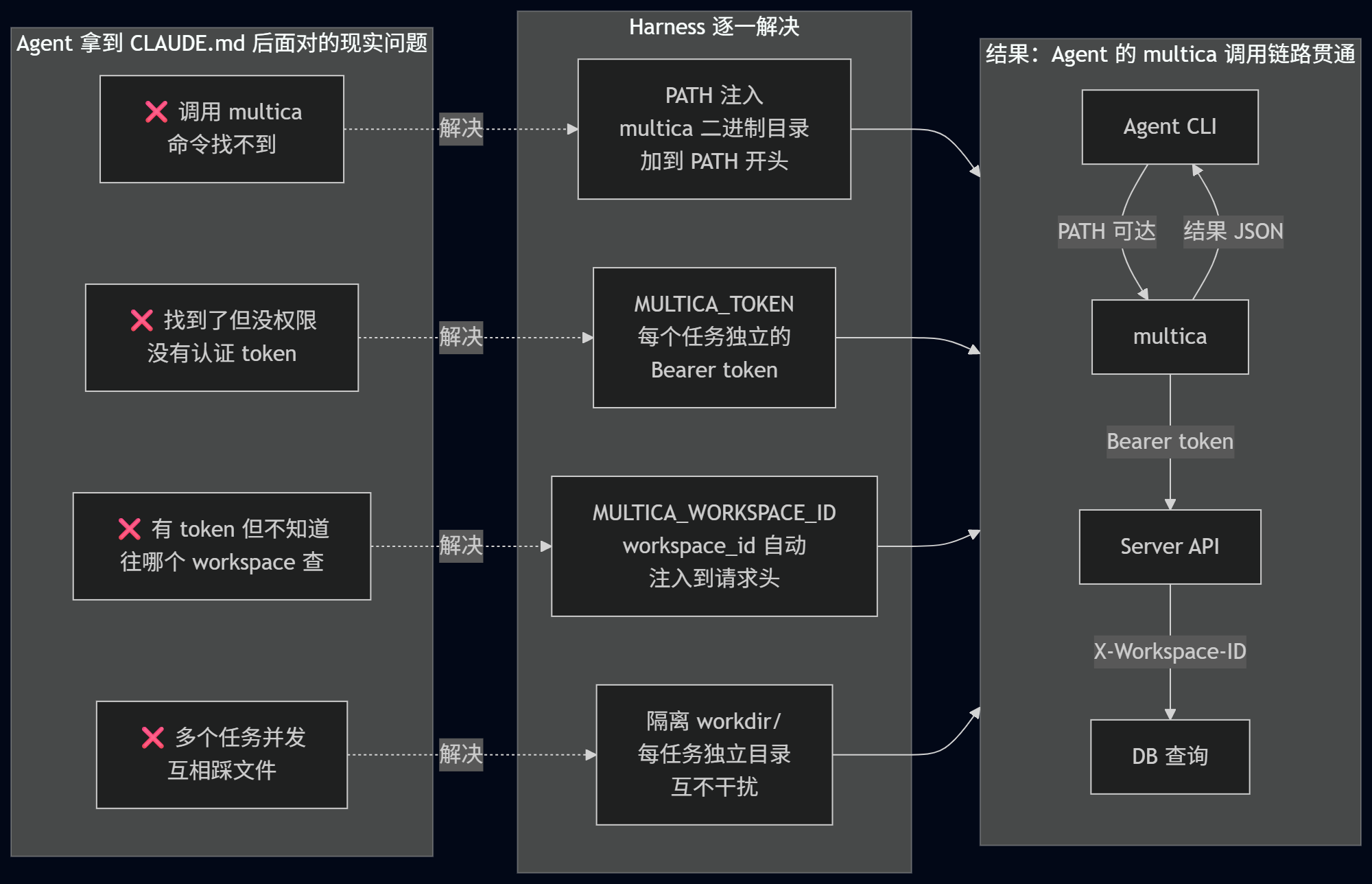
上图就对应代码中 runTask() 的装配过程:(daemon.go)
agentEnv := map[string]string{
"MULTICA_TOKEN": d.client.Token(), // ② 认证凭证
"MULTICA_SERVER_URL": d.cfg.ServerBaseURL, // API 地址
"MULTICA_WORKSPACE_ID": task.WorkspaceID, // ③ workspace 隔离
"MULTICA_AGENT_NAME": agentName, // Agent 身份
"MULTICA_AGENT_ID": task.AgentID,
"MULTICA_TASK_ID": task.ID,
}
// ① 把 multica 二进制所在目录插到 PATH 最前面
agentEnv["PATH"] = binDir + string(os.PathListSeparator) + os.Getenv("PATH")Agent 调用 multica issue get <id> 后,CLI 发出的 HTTP 请求要过三道关卡:

具体来说:
关卡 1 —— 认证(MULTICA_TOKEN → Bearer token):
"MULTICA_TOKEN": d.client.Token() , daemon.go — Harness 注入的 token
关卡 2 —— Workspace 鉴权(RequireWorkspaceMember 中间件):
MULTICA_WORKSPACE_ID 环境变量让 CLI 自动带上这个 header。
这保证 Agent 只能查自己 workspace 的数据——Agent A 在 workspace X 里,绝对查不到 workspace Y 的 issue。
// middleware/workspace.go
func RequireWorkspaceMember(next http.Handler) http.Handler {
// 从 X-Workspace-ID header 取 workspace_id
// DB 查询:这个人是不是这个 workspace 的成员?
// 不是 → 403
}关卡 3 —— Actor 解析(resolveActor()):
这一步的意义是可追溯:Agent 发的评论标记为 author_type = 'agent',创建的 issue 标记为 creator_type = 'agent'。
你在 UI 上看到一条评论,能清楚知道这是BackendBot 说的,不是张三说的。
// handler/handler.go
func (h *Handler) resolveActor(r *http.Request) (actorType string, actorID string) {
agentID := r.Header.Get("X-Agent-ID")
taskID := r.Header.Get("X-Task-ID")
if agentID != "" && taskID != "" {
// 交叉验证:这个 task 确实属于这个 agent?
return "agent", agentID
}
return "member", userID
}transport模块是在讲数据在 Agent 和 Server 之间怎么走, Agent 检索数据的完整路径:

这里有一个容易忽略的细节:--output json 不是可选的格式美化,而是 Agentic RAG 的核心需求。没有这个标志,CLI会输出人类可读的表格(带对齐、颜色代码),Agent 很难解析。
加上 --output json 后返回的是干净的结构化 JSON,Agent 可以精确地按字段读取title、status、assignee_id 等。
