LlamaIndex(原名 GPT Index)是一个开源的数据框架,专门用于构建大语言模型(LLM)应用。它解决了 LLM 的一个核心局限性:LLM 在训练后就无法访问私有数据。LlamaIndex 通过检索增强生成(RAG)技术,将用户的私有数据与 LLM 的生成能力无缝连接。与langchain相比,langchian是编排工具流工作流等,而llamaindex专注于数据格式和数据索引。
LlamaIndex 在 LLM 应用开发栈中处于框架层,介于基础模型层和应用层之间。其内置了多种RAG必须的使用的范式,如:文本切分(Chunking)、向量化(Embedding)、检索(Retrieval)和生成(Generation)。
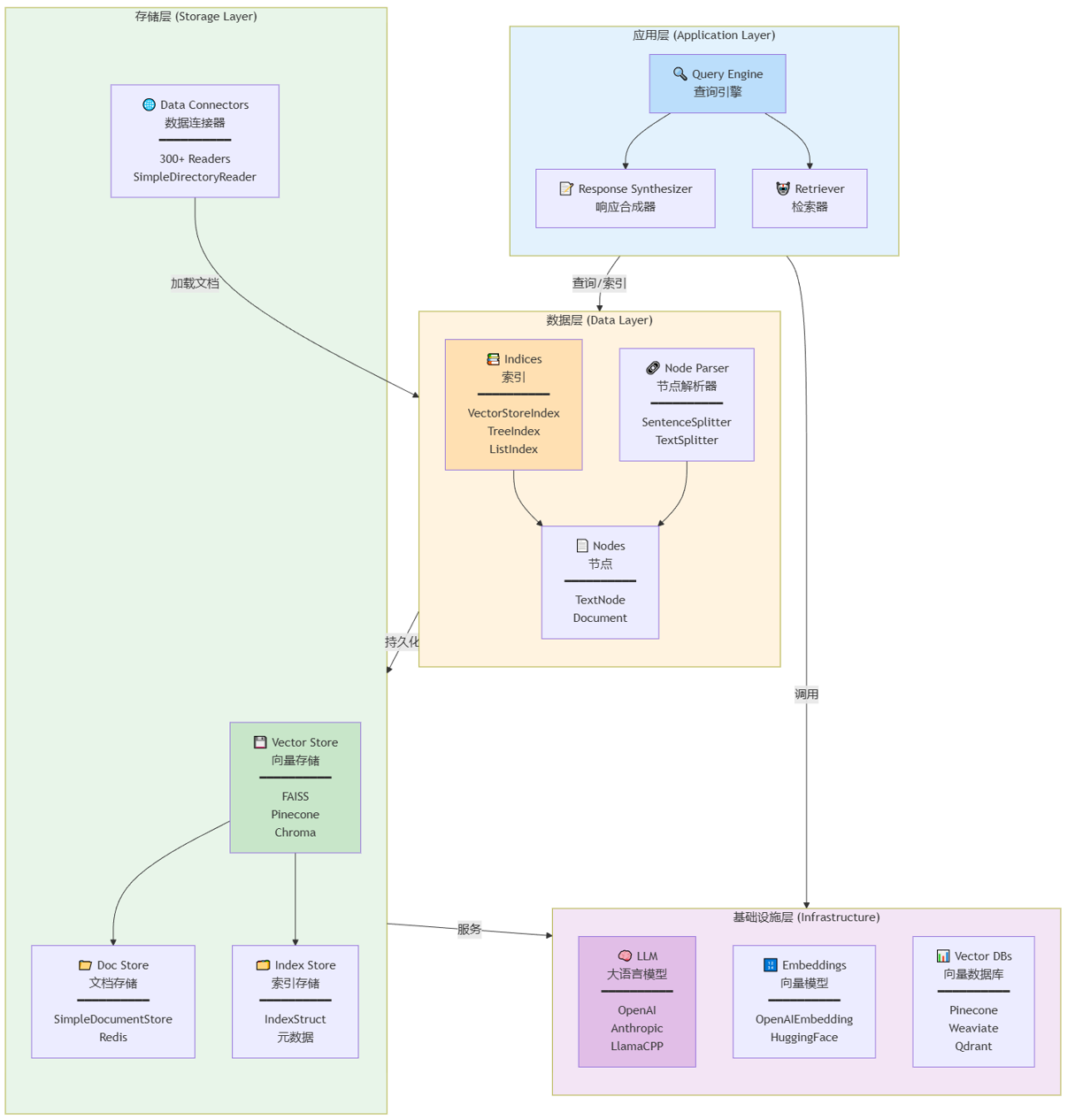
集成了300+的数据连接器:
多种索引策略:
VectorStoreIndex: 向量存储索引(最常用,支持语义检索)
TreeIndex: 树形索引(适合层级式文档)
ListIndex: 列表索引(顺序检索)
KeywordTableIndex: 关键词表索引(精确匹配)
KnowledgeGraphIndex: 知识图谱索引(关系推理)
高级检索能力:
向量检索: 基于语义相似度的 top-k 检索
混合检索: 向量 + 关键词的融合检索
自动合并检索: RecursiveRetriever 自动合并相似节点
路由检索: RouterRetriever 根据查询类型选择不同的检索器
重排序: 检索后使用 Cohere/Rerank 等模型优化结果
多样的response合成模式:
LlamaIndex 主要用于构建以下类型的应用:
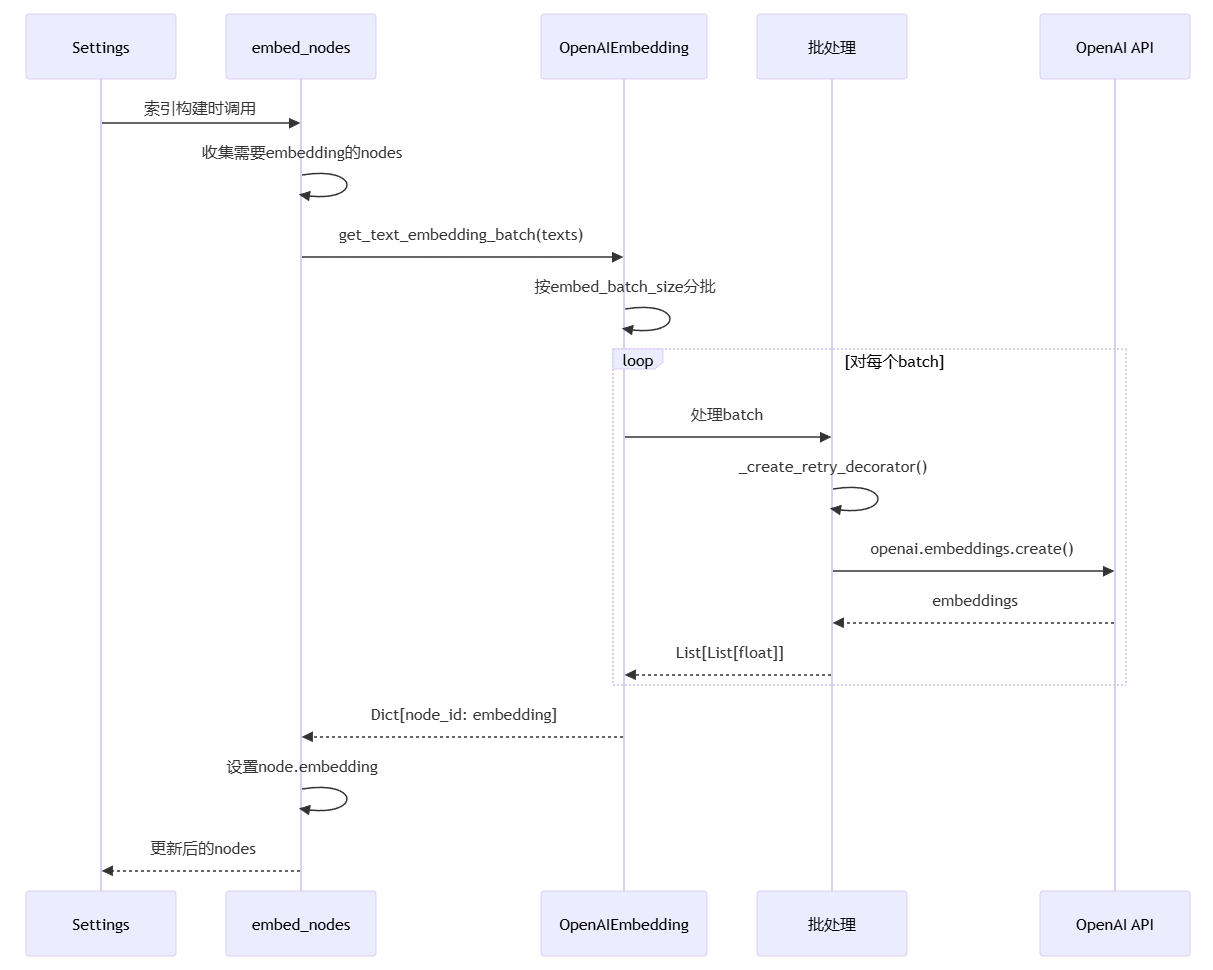
流程说明:
Settings 触发 embed_nodes(),在索引构建时被调用
embed_nodes 收集需要 embedding 的 nodes,筛选出尚未计算向量的节点
调用 OpenAIEmbedding.get_text_embedding_batch(),批量生成向量
按 embed_batch_size 分批处理,避免单次请求过多文本
对每个 batch 创建重试装饰器,处理网络错误和 API 限流
调用 openai.embeddings.create() API,发送文本到 OpenAI 服务
API 返回 embeddings,List[List[float]] 格式的向量列表
返回 Dict[node_id: embedding],建立节点 ID 到向量的映射
设置 node.embedding 属性,将向量附加到每个节点对象
返回更新后的 nodes,完成向量化过程
核心意义:将文本转换为高维向量表示,使语义相似的文本在向量空间中距离相近,支撑后续的向量检索。
索引分为两阶段:阶段一负责数据加载与切分,阶段二负责索引构建与存储。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
# 1. 配置 Settings
Settings.embed_model = OpenAIEmbedding()
Settings.llm = OpenAI(model="gpt-4")
# 2. 加载文档
documents = SimpleDirectoryReader("./data").load_data()
# Shape: List[Document]
# 3. 创建索引
index = VectorStoreIndex.from_documents(documents)
# 内部: Documents -> Nodes -> Embeddings -> VectorStore + DocStore
# 4. 持久化
index.storage_context.persist("./storage")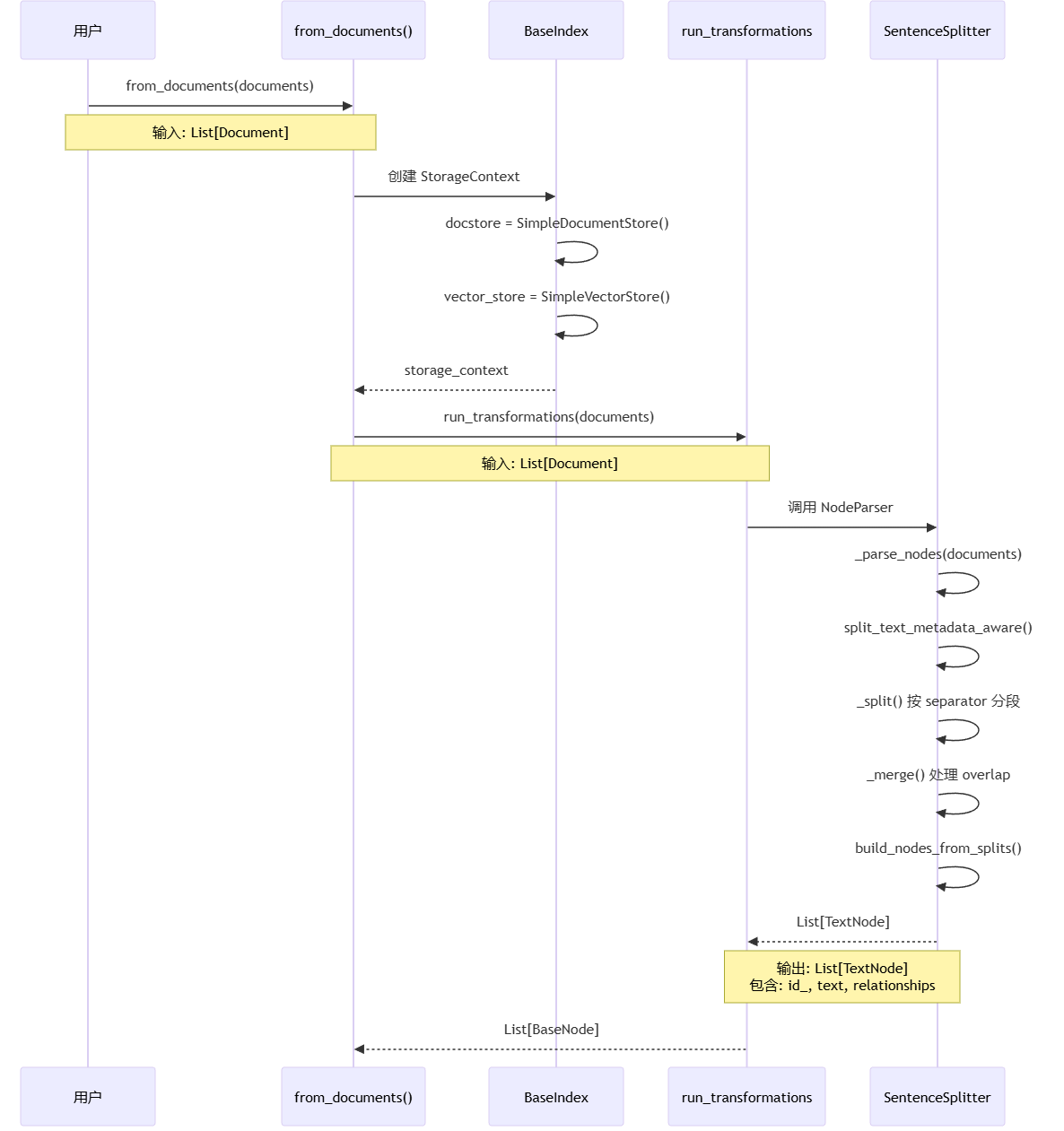
阶段一流程说明:
用户调用 from_documents(documents) 启动索引构建,传入原始文档列表
BaseIndex 创建 StorageContext,初始化 docstore 和 vector_store 用于存储
run_transformations(documents) 调用 NodeParser,将 Documents 转换为 Nodes
SentenceSplitter 执行文档切分:
split_text_metadata_aware(): 根据 metadata 长度调整 chunk_size
_split(): 按 separator(段落、句子)分段
_merge(): 处理 chunk_overlap,确保上下文连贯
build_nodes_from_splits(): 创建 TextNode 对象,建立关系链
返回 List[TextNode],包含切分后的文本节点,如下:
# 数据结构示例
[
TextNode(
id_="node_1",
text="这是文档的第一段内容...",
embedding=None, # 尚未计算向量
metadata={
"file_name": "report.pdf",
"page": 1,
"chunk_index": 0
},
relationships={
NodeRelationship.SOURCE: "doc_123",
NodeRelationship.NEXT: "node_2"
}
),
TextNode(
id_="node_2",
text="这是文档的第二段内容...",
# ... 其他字段
),
# ... 更多节点
]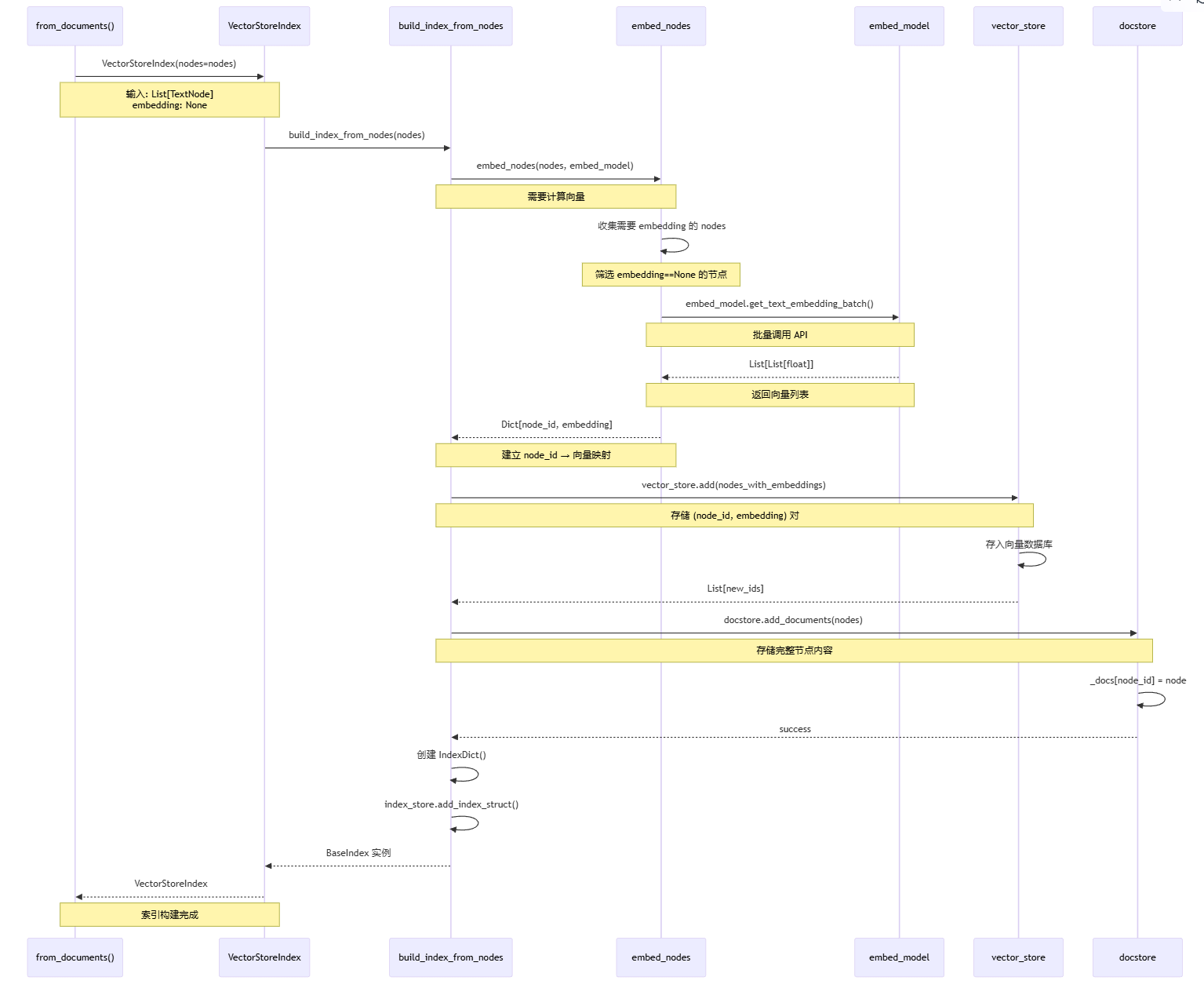
阶段二流程说明:
VectorStoreIndex 初始化,接收 List[TextNode],此时 embedding 全部为 None
build_index_from_nodes() 启动索引构建流程
embed_nodes() 收集并计算 embeddings:
筛选 embedding == None 的节点
提取文本内容调用 embed_model.get_text_embedding_batch()
返回 Dict[node_id: List[float]] 映射
为每个节点设置 embedding 属性
vector_store.add() 存储向量:
将 (node_id, embedding) 对存入向量数据库
用于后续的相似度搜索
docstore.add_documents() 存储完整节点:
将完整的 Node 对象(含 text、metadata)存入文档存储
保持向量索引和文档内容的一致性
创建 IndexDict 并保存到 index_store,记录索引元数据
返回构建完成的 VectorStoreIndex 给用户
查询流程分为两个阶段:阶段一负责检索相关节点,阶段二负责生成最终答案。
# 1. 创建查询引擎
query_engine = index.as_query_engine(
response_mode="compact", # 使用 COMPACT 模式
similarity_top_k=5,
)
# 2. 执行查询
response = query_engine.query("什么是 RAG?")
# 内部: Query -> Embedding -> VectorSearch -> Synthesize -> Response
# 3. 获取结果
print(response.response)
print([node.node.metadata for node in response.source_nodes])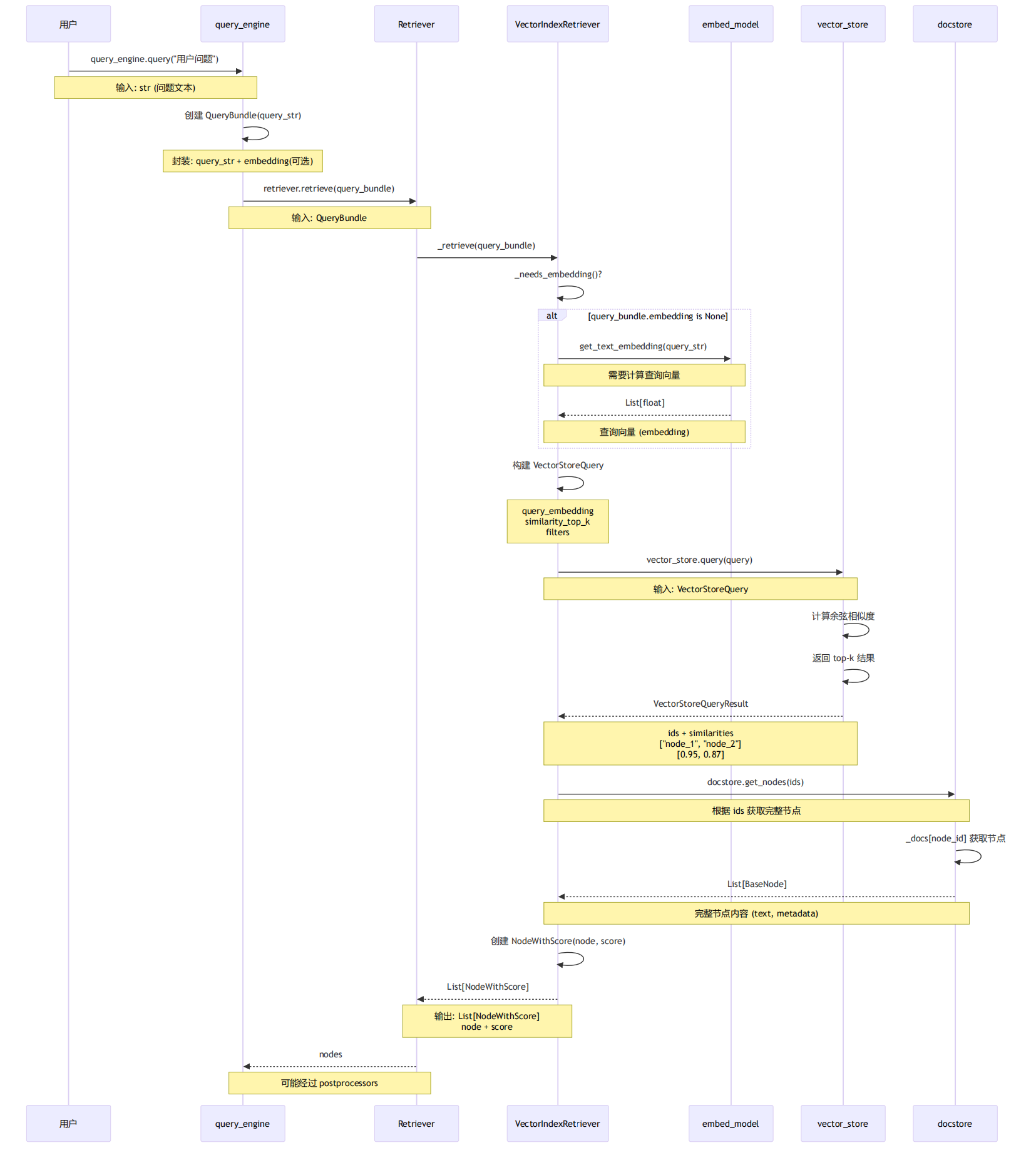
阶段一流程说明:
用户调用 query_engine.query() 发起查询请求,传入问题文本
query_engine 创建 QueryBundle,封装查询字符串和可选的向量表示
retriever.retrieve() 调用 VectorIndexRetriever 执行向量检索
embed_model 为查询生成 embedding(如果尚未计算),将文本转换为向量空间
构建 VectorStoreQuery,包含查询向量、top-k 参数、过滤条件
vector_store.query() 计算余弦相似度,在向量空间中找到最相关的 top-k 节点
返回 VectorStoreQueryResult,包含 node_id 列表和相似度分数
docstore.get_nodes() 获取完整节点内容,根据 node_id 补充完整文本和元数据
创建 NodeWithScore 对象,将节点和相似度分数封装在一起
返回 List[NodeWithScore],作为检索结果传递给后续的合成阶段
核心意义:通过向量相似度在向量空间中找到与用户问题语义最相关的内容。
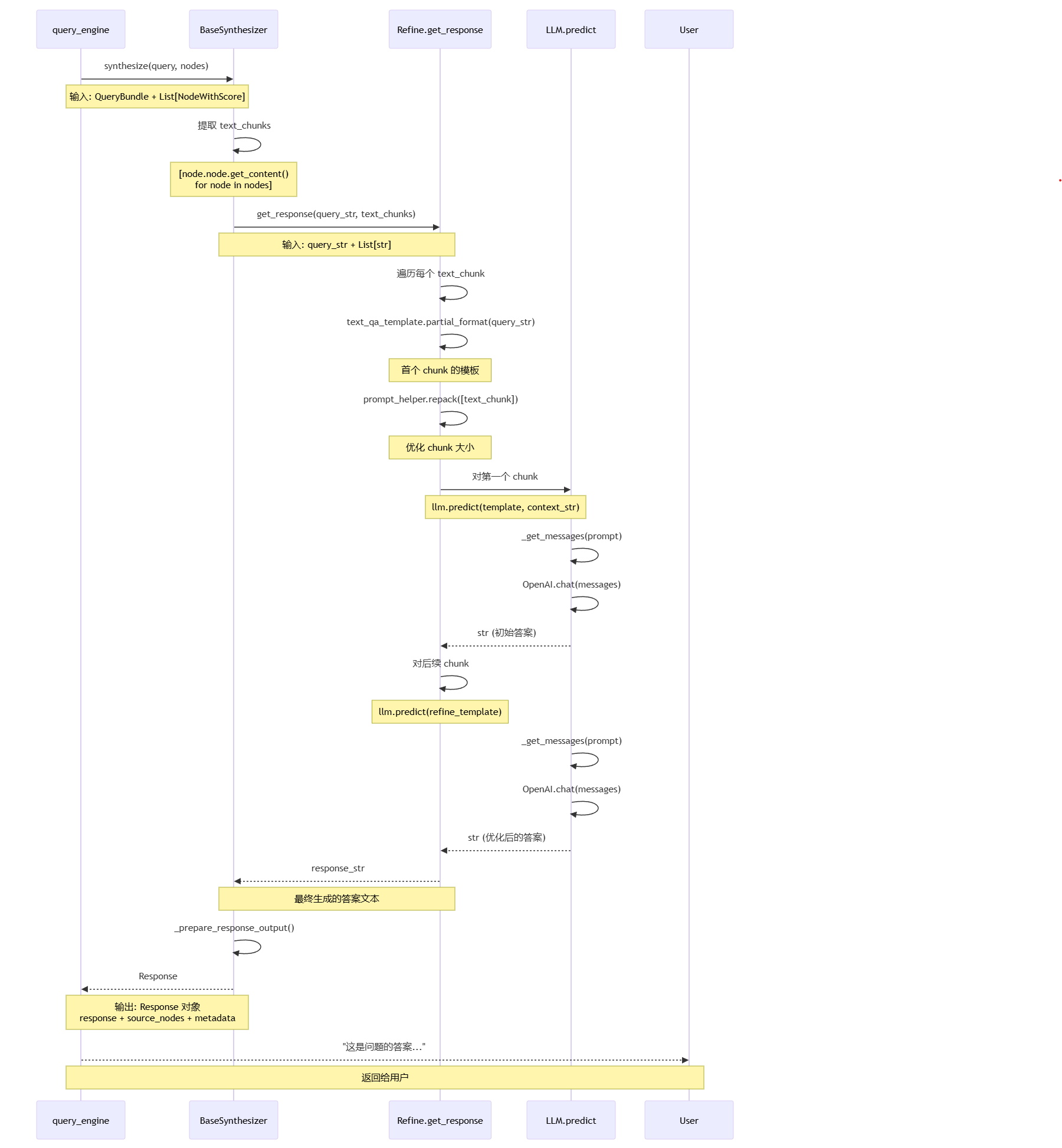
阶段二流程说明:
query_engine 调用 response_synthesizer.synthesize(),传入 QueryBundle 和检索到的节点
BaseSynthesizer 提取节点内容,从 NodeWithScore 中提取 text 字段
get_response() 遍历每个 text_chunk,对每个检索到的文本块进行处理
首次调用使用 text_qa_template:
partial_format(query_str) 填充查询字符串
prompt_helper.repack() 优化 chunk 大小
llm.predict(template, context_str) 生成初始答案
后续调用使用 refine_template:
partial_format(query_str, existing_answer) 填充查询和已有答案
检查 available_chunk_size 确保不超限
llm.predict(refine_template) 生成优化后的答案
合成最终答案,将所有 chunk 的处理结果合并
构建 Response 对象,包含答案文本、引用的源节点和元数据
返回 Response 给用户
核心意义:通过检索增强生成(RAG),结合向量检索找到相关上下文,再通过 LLM 生成准确、有依据的答案。
在查询的Synthesize阶段中,最重要的就是把get_response() 遍历每个 text_chunk的时候,按照什么方式来调用LLM,这里有四种模式的response合成,其差异在概述里提到过。
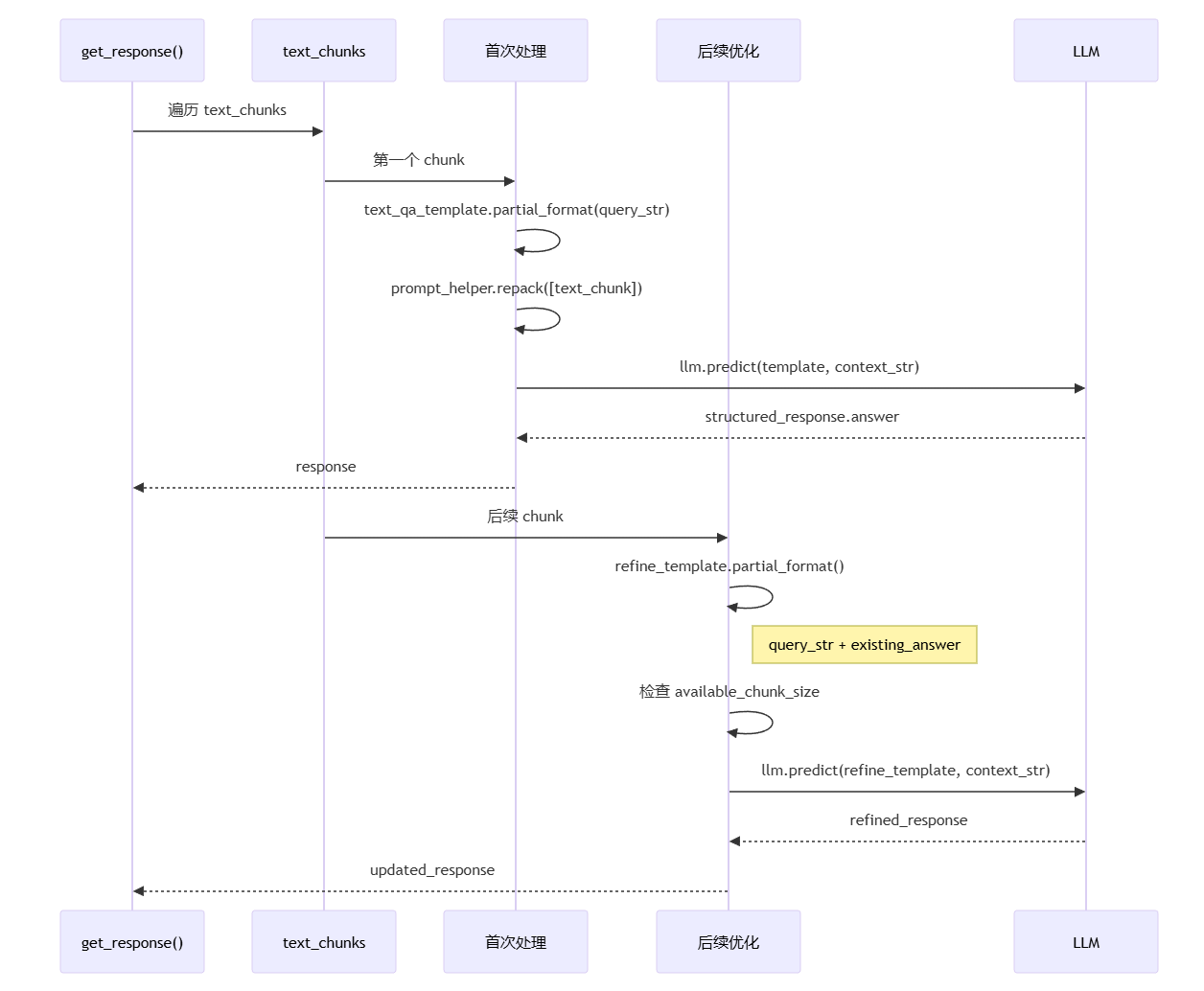
流程说明:
get_response() 遍历 text_chunks,对每个检索到的文本块进行处理
第一个 chunk 调用首次处理逻辑,使用 text_qa_template 生成初始答案,首次调用的template和后续调用的template不一样
text_qa_template.partial_format() 填充查询字符串,准备 QA 模板
prompt_helper.repack() 优化 chunk 大小,确保不超过 context window
llm.predict() 生成初始答案,基于第一个 chunk 的内容
后续 chunk 调用优化逻辑,使用 refine_template 逐步改进答案
refine_template.partial_format() 填充现有答案,将已有答案作为上下文
检查 available_chunk_size,确保模板和上下文能放入 context window
llm.predict() 生成优化后的答案,结合当前 chunk 和之前的答案
返回最终更新后的 response
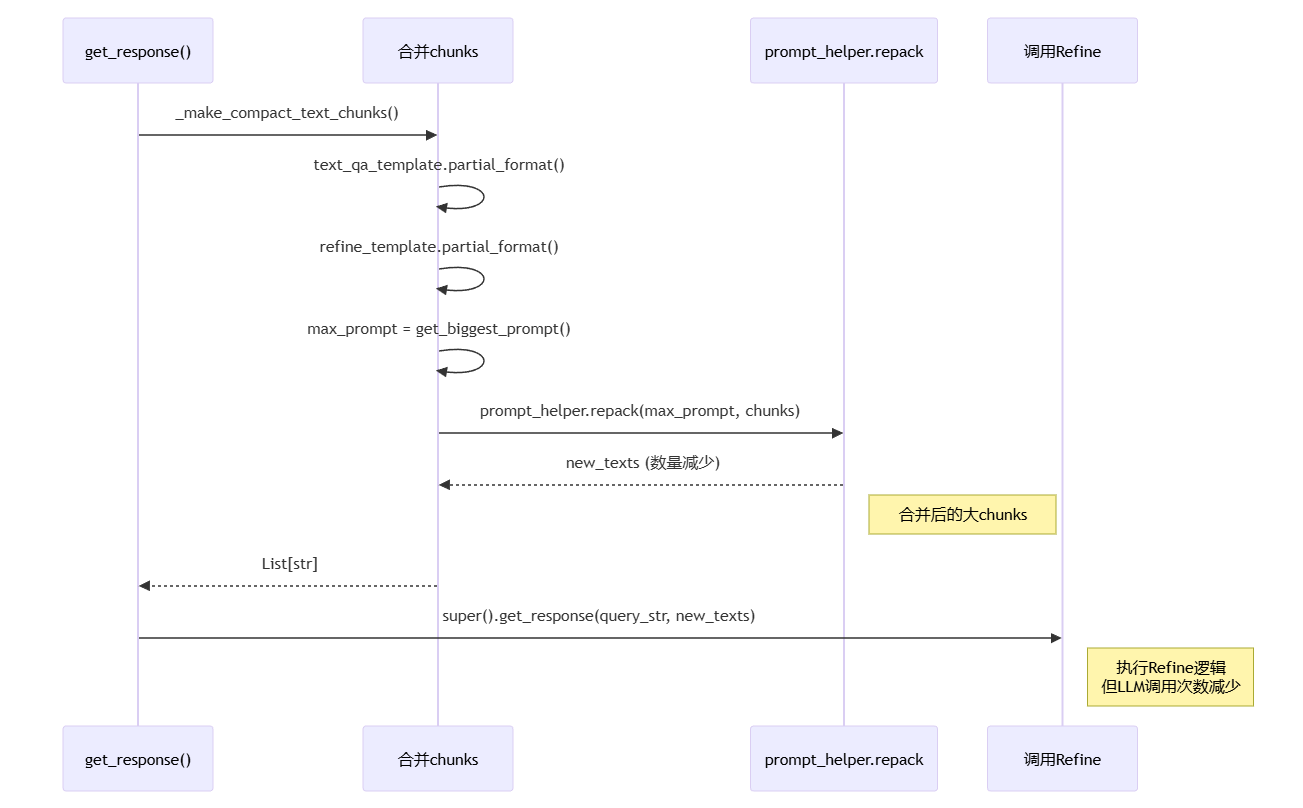
流程说明:
get_response() 调用 makecompact_text_chunks(),执行智能合并逻辑
分别格式化两种模板,text_qa_template 和 refine_template 都需要考虑
get_biggest_prompt() 选择最大的模板,确保合并后的 chunks 能放入任何一个模板
prompt_helper.repack() 合并小 chunks,将多个小文本块重新打包成大块
返回数量减少的 new_texts,减少后续 LLM 调用次数
调用父类 Refine.get_response(),在合并后的大 chunks 上执行迭代优化
核心意义:通过预先合并减少 LLM 调用次数,在保证答案质量的同时提升性能,是默认推荐的模式。
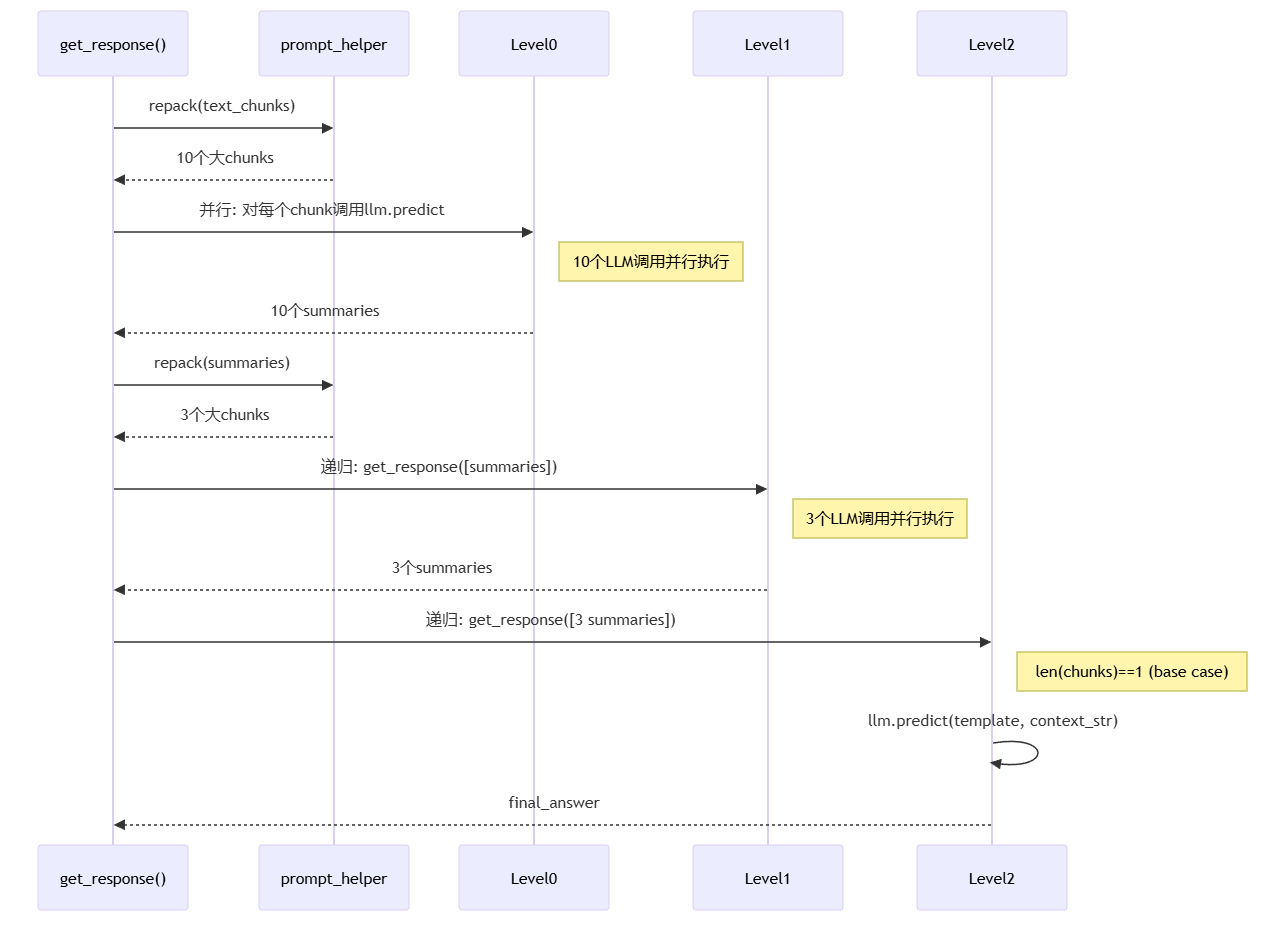
流程说明:
get_response() 调用 prompt_helper.repack(),将原始 chunks 重新打包
返回多个大 chunks,例如 10 个原始 chunks 变成 10 个大 chunks
Level 0: 并行调用 llm.predict(),对每个大 chunk 生成摘要,可并行执行
收集 10 个 summaries,作为下一层的输入
Level 1: 递归调用 get_response(),处理 summaries 列表
再次 repack(),将 10 个 summaries 合并为 3 个更大的 chunks
并行调用 llm.predict(),生成 3 个二级 summaries
Level 2: 再次递归,处理 3 个 summaries
达到 base case,len(chunks) == 1 时执行最终调用
llm.predict() 生成 final_answer
核心意义:树形递归结构,每层内可并行处理,适合大量节点的汇总场景,平衡了速度和质量。
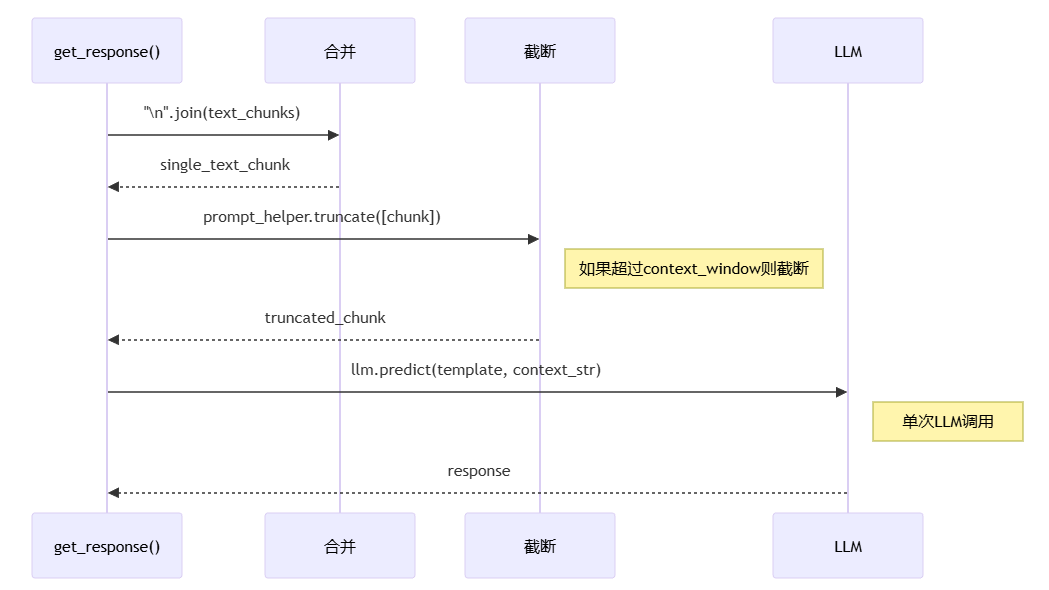
流程说明:
get_response() 调用 join 操作,使用 "\n" 连接所有 text_chunks
生成 single_text_chunk,合并所有检索到的文本
prompt_helper.truncate() 检查并截断,如果超过 context window 则截断
返回 truncated_chunk,确保能放入 LLM 的上下文窗口
llm.predict() 单次调用生成 response,一次性处理所有上下文
核心意义:最简单直接的方式,单次 LLM 调用,但超长上下文会被截断,可能丢失信息。
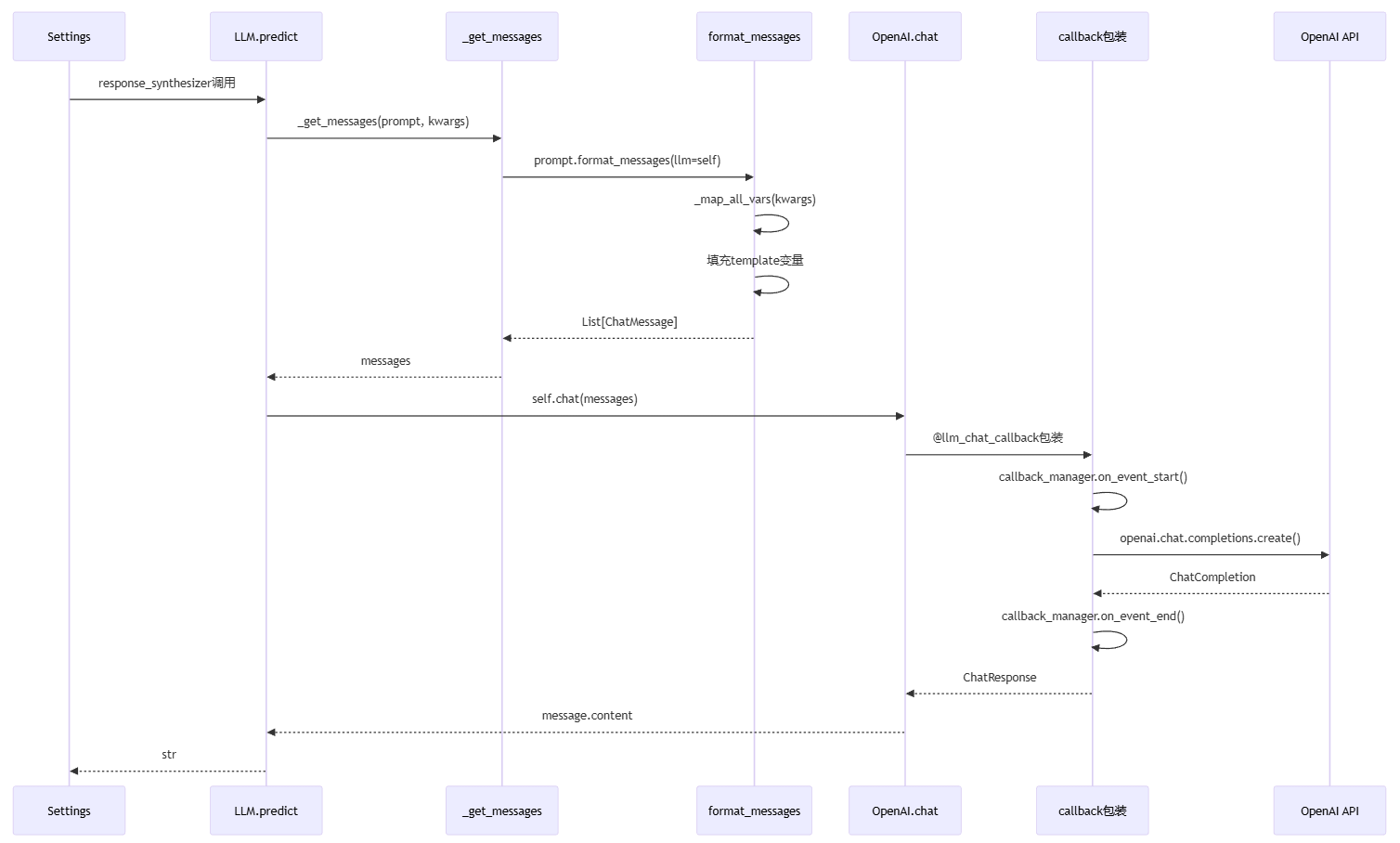
流程说明:
Settings 触发 LLM.predict(),response_synthesizer 发起 LLM 调用
LLM.predict 调用 getmessages(),将 prompt 转换为消息格式
prompt.format_messages() 填充模板变量,调用 mapall_vars 处理参数
填充 template 变量,将 kwargs 中的值替换到模板占位符
返回 List[ChatMessage],格式化后的消息列表
LLM.predict 调用 self.chat(messages),执行聊天 API 调用
@llm_chat_callback 装饰器包装调用,添加事件追踪和监控
callback_manager.on_event_start() 触发开始事件,记录 LLM 调用开始
调用 openai.chat.completions.create() API,发送消息到 OpenAI 服务
API 返回 ChatCompletion,包含生成的响应和元数据
callback_manager.on_event_end() 触发结束事件,记录 LLM 调用结束
提取 message.content,从 ChatResponse 中获取生成的文本
返回 str 格式的响应,给调用方
核心意义:统一封装 LLM 调用接口,支持多种 LLM 提供商,通过 callback 机制实现可观测性,为 RAG 系统提供生成能力。
class Document(Node):
"""文档对象,表示一个完整的数据源(如一个文件)"""
id_: str # 唯一标识符
text_resource: MediaResource # 文本内容和元数据
metadata: Dict[str, Any] # 文件路径、创建时间等
excluded_embed_metadata_keys: List[str] # Embedding 时排除的元数据
excluded_llm_metadata_keys: List[str] # LLM 时排除的元数据
embedding: Optional[List[float]] # 延迟计算的向量
示例:
Document(
id_="doc_123",
text_resource=MediaResource(text="这是一篇文档的内容..."),
metadata={"file_name": "report.pdf", "page": 1}
)
class TextNode(BaseNode):
"""文本节点,表示文档切分后的一个语义单元"""
id_: str # 节点唯一标识
text: str # 节点文本内容
embedding: Optional[List[float]] # 向量表示
metadata: Dict[str, Any] # 继承自 Document
relationships: Dict[NodeRelationship, RelatedNodeInfo]
start_char_idx: Optional[int] # 在原文档中的起始位置
end_char_idx: Optional[int] # 在原文档中的结束位置
Relationships 类型:
SOURCE: 指向原 Document
PREVIOUS: 指向前一个节点
NEXT: 指向后一个节点
PARENT: 指向父节点
class NodeWithScore(BaseComponent):
"""带分数的节点,用于检索结果"""
node: BaseNode # 节点对象
score: Optional[float] # 相似度分数或其他评分
class QueryBundle(DataClassJsonMixin):
"""查询对象,封装查询字符串和其向量表示"""
query_str: str # 查询字符串
embedding: Optional[List[float]] # 延迟计算的查询向量
custom_embedding_strs: Optional[List[str]] # 自定义嵌入字符串
class Response:
"""查询响应对象"""
response: str # 生成的答案
source_nodes: List[NodeWithScore] # 引用的节点
metadata: Optional[Dict[str, Any]] # 额外元数据
class IndexDict(IndexStruct):
"""向量索引结构元数据"""
index_id: str # 索引ID
summary: Optional[str] # 索引摘要
nodes_dict: Dict[str, IndexNode] # 节点映射
doc_id_dict: Dict[str, List[str]] # 文档到节点的映射
