先说说我的看法,现在各种评价满天飞,我看了看README,其实很好说理解,首先肯定是OCR。
在README中提到两个文件,一个是对image进行OCR,一个是对PDF进行OCR。其最主要的功能就是将其文字和图片进行提取,然后改变为可执行对象。
其次就是对image进行理解,将其转为文字的描述,详细的可以看下图:

我说一下我的思考,受限于我的认知,仅供参考,如果你有更好的想法,欢迎联系我,很乐意跟您进一步讨论。首先是OCR,这个功能的思考肯定源自于多模态大模型的实际业务,对PDF和image的tokenlization是多模态的基础,特别是tob中台的各种文档的token化,这是对agent inference体系中的context engine的PDF给出了一个解法,只要是实际思考过中台文档类的业务,这个是必然要做的工作。
传统的知识图谱的工作优化无穷无尽,这里可以看这个讲座,而deepseek给出的解法是双视觉模型:SAM提供精确定位 + CLIP提供语义理解,然后解析出来XML的字典。这非常有意思,这就是经典的深度学习打破传统dirty逻辑判断的例子,我也相信这种垂类的高效模型是非常的有前途的,我期待agent inference体系下构建起一套多方法多模型的解决方案,最近还看到了智谱和清华的训练模型的多模态解决方案,挖个坑。
除了体系上作为不可或缺的一部分,其次还有两个点非常发人深思,两个都源自数字生命卡兹克的一篇博文,写的非常好,非常推荐阅读。
一个是他提出的比喻,一个1000轮的上下文,token必然是爆炸的,但是如果我只让agent保留了最近10轮,其他990轮都保存为图片,就像你给聊天记录截了个屏。然后调用双视觉模型进行encoder压缩成视觉的token,等到prompt提到了之前的内容,agent就会去扫视一圈视觉token,只拿匹配的内容解码成原来的内容。这里有一个核心的思想,就是压缩内容,提取出key context来代表该轮对话,这个提取太重要了,正是这个压缩提取信息 + 解码获得完整信息思路的实现,验证了压缩token的合理性和可行性。
第二个是渐进式的信息丢失模式。人类的记忆会随着时间的推移而衰退,人类的视觉感知会随着空间距离的拉远而退化。DeepSeek说,对于那些更古老的上下文,我们可以逐步缩小渲染出的图像,以进一步减少令牌消耗。刚看到的时候,我是震撼的,我从未想过压缩context能使用这个思路,太棒了。那我们发散思维,是否能给其建立一个仿照大脑记忆思路的context engine,依赖于大脑的记忆注意力机制。又或者说建立一个权重机制,进行全局key context的统计,在这个时期出现的key context权重上升,就多参考这部分的token。又或者说在有关联的key context之间建立关系网络,往往相似或者相反的context也是需要的内容,我们需要辩证的去思考,大模型也需要辩证的数据进行输入。
源码明天继续吧,12点了,该睡了
猴,睡醒了,接着写()
主执行流程如下:
# 第一步:PDF渲染为图像
images = pdf_to_images_high_quality(INPUT_PATH)
# 第二步:多线程并行并行处理所有页面的图像预处理
# 使用ThreadPoolExecutor创建线程池
# max_workers=NUM_WORKERS: 并行线程数(默认64)
with ThreadPoolExecutor(max_workers=NUM_WORKERS) as executor:
# executor.map(): 并行映射process_single_image到所有图像
# tqdm(): 显示预处理进度条
batch_inputs = list(tqdm(
executor.map(process_single_image, images),
total=len(images),
desc="Pre-processed images"
))
# 第三步:使用vLLM引擎并行推理所有页面
outputs_list = llm.generate(
batch_inputs, # 所有页面的推理请求列表
sampling_params=sampling_params # 采样参数(温度、最大token数等)
)
# 返回:List[RequestOutput],每个包含一个页面的OCR结果
# outputs_list[i].outputs[0].text 对应 images[i] 的OCR文本
# 第四步:输出
for output, img in zip(outputs_list, images):
# 提取当前页面的OCR文本
content = output.outputs[0].text
# 创建图像副本用于绘制
image_draw = img.copy()
# 正则提取所有标注信息
matches_ref, matches_images, mathes_other = re_match(content)
# 绘制边界框和标签
# 同时自动裁剪保存图像区域(如果有)
result_image = process_image_with_refs(image_draw, matches_ref, jdx)
# 添加到可视化图像列表(用于生成标注PDF)
draw_images.append(result_image)
# 保存原始标注文件(用于调试和二次处理)
with open(mmd_det_path, 'w', encoding='utf-8') as afile:
afile.write(contents_det)
# 保存清理后的Markdown文件(最终可读版本)
with open(mmd_path, 'w', encoding='utf-8') as afile:
afile.write(contents)
# 将所有标注图像合成为PDF(可视化验证)
pil_to_pdf_img2pdf(draw_images, pdf_out_path)那其实我感觉最关键的有以下几个点:
在推理之前,对PDF做了什么处理
推理的具体细节
推理之后,如何组合输出
言简意赅的说就是把PDF改成图片,然后跟图片一样去处理,这样就把pdf归总到图片那边去了,具体架构如下图:
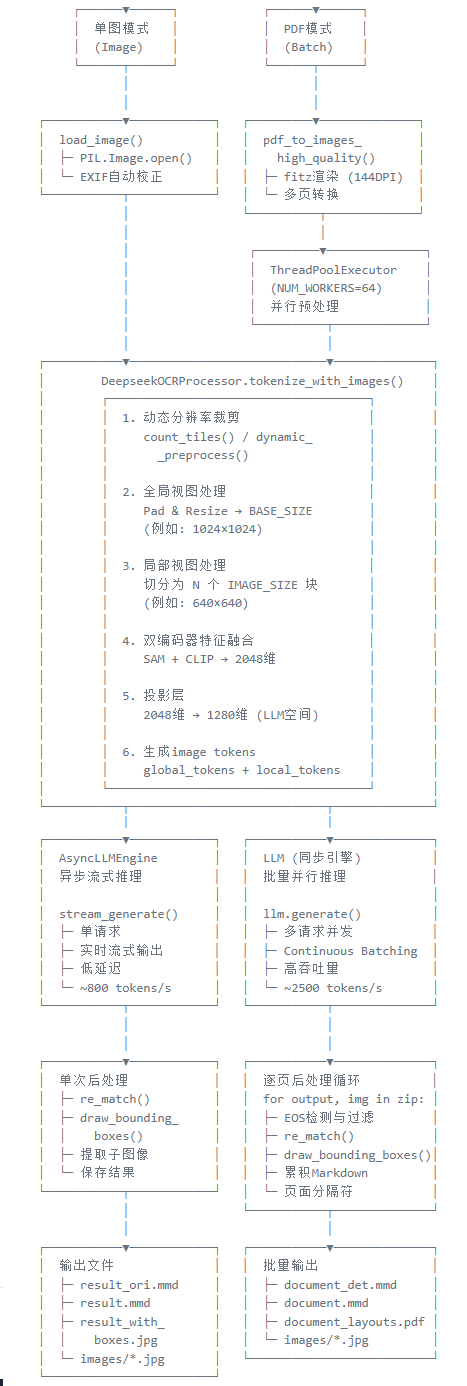
而其最核心的部分是 DeepseekOCRProcessor.tokenize_with_images() ,也就是在论文中的下图:
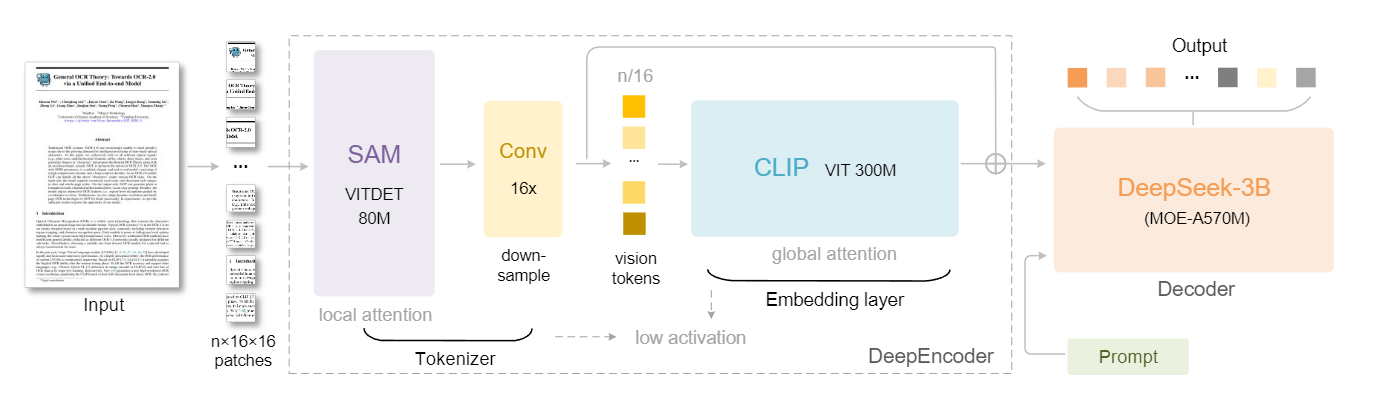
这里有一个动态切分patches的工作,为的就是在后续encoder images时可以选择全局encoder或者局部 + 全局encoder的方案
切分完的图片进入SAM获得视觉特征,进行tokenlization
SAM出来的数据通过卷积进行16倍的压缩,是一个下采样
然后把下采样的vision token输入进CLIP进行全局attention
通过残差结构输出 + prompt给deepseek 3B进行解码,也就是语义理解和输出任务结果
上面的过程映射到源码如下图:
PDF文件 (run_dpsk_ocr_pdf.py)
│
├─ pdf_to_images_high_quality()
│ └─ 返回: List[PIL.Image]
│
├─ ThreadPoolExecutor.map(process_single_image, images)
│ └─ 每个页面调用:
│ └─ DeepseekOCRProcessor().tokenize_with_images()
│ └─ 返回: [[input_ids, pixel_values, images_crop, ...]]
│
├─ llm.generate(batch_inputs) # vLLM批量推理
│ └─ 内部调用:
│ └─ DeepseekOCRForCausalLM.forward()
│ └─ self._process_image_input()
│ └─ self._pixel_values_to_embedding()
│ │
│ ├─ self.sam_model(patches) # SAM调用
│ ├─ self.vision_model(patches, sam_features) # CLIP调用
│ ├─ self.sam_model(image_ori) # SAM调用
│ └─ self.vision_model(image_ori, sam_features) # CLIP调用
│
└─ 返回OCR结果,进行后处理首先是对于图片进行并行处理,run_dpsk_ocr_pdf.py中的process_single_image():
prompt_in = prompt # 使用全局提示词
# 构建推理输入数据结构
cache_item = {
"prompt": prompt_in, # OCR处理提示词
"multi_modal_data": {
"image": DeepseekOCRProcessor().tokenize_with_images(
images=[image], # 输入图像列表
bos=True, # 添加开始标记
eos=True, # 添加结束标记
cropping=CROP_MODE # 图像裁剪模式
)
},
}在image_process.py 的DeepseekOCRProcessor 中,我们可以清晰的看到三个核心处理函数:
def encode(self, text: str, bos: bool = True, eos: bool = False)
"""
将文本编码为token ID序列
参数:
text (str): 输入文本
bos (bool): 是否在开头添加BOS token(默认True)
eos (bool): 是否在结尾添加EOS token(默认False)
返回:
List[int]: token ID列表
"""
def decode(self, t: List[int], **kwargs) -> str
"""
将token ID序列解码为文本
参数:
t (List[int]): token ID列表
**kwargs: 传递给tokenizer.decode的额外参数
返回:
str: 解码后的文本
"""
def tokenize_with_images(self,
images: List[Image.Image],
bos: bool = True,
eos: bool = True,
cropping: bool = True,
)
"""
参数:
images (List[PIL.Image]): 输入图像列表
bos (bool): 是否添加BOS token
eos (bool): 是否添加EOS token
cropping (bool): 是否启用动态裁剪
返回:
List[List]: 嵌套列表,包含:
[
[
input_ids, # Token序列 [seq_len]
pixel_values, # 全局视图 [n_imgs, 3, BASE_SIZE, BASE_SIZE]
images_crop, # 局部裁剪 [1, n_crops, 3, IMAGE_SIZE, IMAGE_SIZE]
images_seq_mask, # 图像token掩码 [seq_len]
images_spatial_crop,# 裁剪比例 [n_imgs, 2]
num_image_tokens, # 每张图的token数
image_shapes # 原始图像尺寸
]
]
处理流程:
对于prompt "<image>\n<|grounding|>Convert to markdown."
1. 分割为 ["", "\n<|grounding|>Convert to markdown."]
2. 处理第一个分割(空字符串)→ tokenize
3. 处理对应的图像 → 生成image tokens
4. 处理第二个分割(提示词)→ tokenize
5. 合并所有tokens
"""可以看到,返回了一堆处理后的对象,在多线程处理完图像之后,在run_dpsk_ocr_pdf.py中,开启了llm进行推理,该LLM的配置可以从文件头里找到:
outputs_list = llm.generate(
batch_inputs, # 预处理后的批量输入数据
sampling_params=sampling_params # 采样参数(温度、最大token等)
)在deepseek_ocr.py 的DeepseekOCRForCausalLM 类中的init方法就可以找到两个模型的对象:
self.sam_model = build_sam_vit_b()
self.vision_model = build_clip_l()llm执行的generate 默认是执行前向传播的forward,在forward函数我们找到了对多模态数据的处理,执行函数链为:
forward() # 前向传播
-> get_multimodal_embeddings() # 图像输入转换为语言模型可用的嵌入
--> _parse_and_validate_image_input() # 拿到输入数据
--> _process_image_input() # 处理图像并返回视觉嵌入
---> _pixel_values_to_embedding() # 像素值转视觉嵌入的核心算法
-> get_input_embeddings() # 融合文本和视觉嵌入
-> language_model() # inference在_pixel_values_to_embedding() 中,找到了输入模型和融合数据的代码:
# 提取当前图像的切片数据(转换为bfloat16提高效率)
patches = images_crop[jdx][0].to(torch.bfloat16) # batch_size = 1
# 提取当前图像的全局视图数据
image_ori = pixel_values[jdx]
# 提取切片空间配置 [width_tiles, height_tiles]
crop_shape = images_spatial_crop[jdx][0]
# 对全局视图执行相同的双编码器处理
# SAM编码器:专注于精确的空间定位和边界检测
global_features_1 = self.sam_model(image_ori)
# CLIP编码器:专注于语义理解,使用SAM特征作为补充
global_features_2 = self.vision_model(image_ori, global_features_1)
# 特征拼接
# Shape: [batch, seq_len, 1024] + [batch, seq_len, 1024] -> [batch, seq_len, 2048]
global_features = torch.cat((
global_features_2[:, 1:],
global_features_1.flatten(2).permute(0, 2, 1)
), dim=-1)
# 特征投影:2048维 -> 1280维(语言模型嵌入空间)
global_features = self.projector(global_features)如果是局部的特征进行,最后还需要排序一下,最终是局部 + 全局 + 分隔符。最后get_input_embeddings()把原来image的位置替换为vit出来的text,如下:
原始序列: [BOS] 请识别 <image> 中的文字 [EOS]
↓ 替换
融合序列: [BOS] 请识别 [vis_feat_1][vis_feat_2]...[vis_feat_N] 中的文字 [EOS]替换之后就进入llm进行推理,输出为XML的结构化结果。
这个XML的结构化是deepseek根据传统知识图谱的方式进行的结构化标记语言的设计,简单说一下就是用特殊的token进行标记:
# 在tokenizer中预定义的特殊token
special_tokens = [
'<|ref|>', # 引用开始标记
'<|/ref|>', # 引用结束标记
'<|det|>', # 检测/定位开始标记
'<|/det|>', # 检测/定位结束标记
'<|grounding|>' # 定位任务触发标记
]然后用坐标计算去定位的,比如说:
<|ref|>title<|/ref|><|det|>[[89, 123, 567, 234]]<|/det|>
# 销售报告2024年第一季度
<|ref|>paragraph<|/ref|><|det|>[[45, 267, 890, 356]]<|/det|>
本季度公司销售业绩表现良好,总营收达到1200万元,同比增长15%。
<|ref|>table<|/ref|><|det|>[[100, 400, 800, 650]]<|/det|>
| 产品类别 | 销量 | 营收(万元) |
|----------|------|------------|
| 手机 | 1500 | 450 |
| 电脑 | 800 | 640 |
| 配件 | 2200 | 110 |
<|ref|>image<|/ref|><|det|>[[200, 700, 600, 900]]<|/det|>
[销售趋势统计图表]其中的格式就如[[x1, y1, x2, y2]] 或 [[x1, y1, x2, y2], [x3, y3, x4, y4]] 。不同的元素用不同的标记:
# 常见的元素类型
element_types = [
'title', # 标题
'paragraph', # 段落
'table', # 表格
'image', # 图像
'list', # 列表
'formula', # 公式
'chart', # 图表
'header', # 页眉
'footer', # 页脚
'caption' # 标题/说明
]而这种结构化数据在训练的时候会设计多损失函数的组合:
# 多任务损失函数组合
total_loss = (
α * content_loss + # 内容识别损失
β * structure_loss + # 结构解析损失
γ * coordinate_loss + # 坐标预测损失
δ * format_loss # 格式一致性损失
)推理的时候会根据结构触发结构化输出:
# 通过特殊prompt触发结构化输出
prompts = {
"structured": "<image>\n<|grounding|>Convert the document to markdown.",
"free_ocr": "<image>\nFree OCR.", # 纯文本OCR
"locate": "<image>\nLocate <|ref|>标题<|/ref|> in the image." # 定位任务
}后处理会在parse_structured_output函数里找到提取和解析标记块和对应的坐标计算,可视化输出会在visualize_detection去标记检测的结果。有需要请自行翻翻代码。
这是一套非常简洁而又高效的OCR系统,对于每个功能都设计了独立的流程和对应的解决方案,是非常非常好的落地工作,如果以后遇到了类似的工作,还是会回来参考的。
