上文中,我们运行了一个简单的cuda函数,并且一次过的将其运行了起来,这次,我们需要补充一些基础的概念,通过概念和框架的建立,我们才能走的更远,高屋建瓴的认识更多。
继续沿用上次的hello world代码,可能名字有点修改,问题不大,请务必看清楚文件名!
新建一个result目录:
sudo mkdir –m 777 buiild测试一下没问题:
(base) moyu@DESKTOP-5C0FGMS:~/cuda_study$ nvcc -g -G -O0 -o ./build/hello ./course1/hello.cu
nvcc warning : Support for offline compilation for architectures prior to '<compute/sm/lto>_75' will be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
(base) moyu@DESKTOP-5C0FGMS:~/cuda_study$ ./build/hello
CPU: Hello world!
thread idx: 96
thread idx: 97
thread idx: 98原因是vscode的c_cpp_properties.json没有锁定到对应的目录,把cuda的include导进来,还有把编译的地址改到nvcc上:
{
"configurations": [
{
"name": "Linux",
"includePath": [
"${workspaceFolder}/**",
"/usr/local/cuda/include"
],
"defines": [],
"compilerPath": "/usr/local/cuda/bin/nvcc",
"cStandard": "c17",
"cppStandard": "gnu++17",
"intelliSenseMode": "linux-gcc-x64"
}
],
"version": 4
}先安装,不安装可能会报错:
sudo apt install libssl-dev进入CMake官网,选择最新的下载版本,下载(收手吧阿祖,先往下看,我炸锅了,别你也中招了)
直接拖到vscode中,不要放在源代码下进行解压,丢到别的地方,然后解压,安装:
mv cmake-4.1.0.tar.gz ../
tar -zxvf cmake-4.1.0.tar.gz
cd cmake-4.1.0
./bootstrap --prefix=/usr/local/cmake
make
make install炸锅了,不要用4,版本太高了,cuda报错了(难绷)
mv cmake-3.28.4.tar.gz ../
tar -zxvf cmake-3.28.4.tar.gz
cd cmake-3.28.4
./bootstrap --prefix=/usr/local/cmake
make
sudo make install在bash中写入cmake :
# 1、打开环境配置文件
vim ~/.bashrc
# 2、写入环境 这里是上面指定安装目录的文件地址
export PATH="/usr/local/cmake/bin:$PATH"
# 3、激活环境
source ~/.bashrc检查是否安装成功:
# 查看版本
cmake --version
# 查看位置
which cmake如果报错:
CMake Error at Utilities/cmcurl/CMakeLists.txt:993 (message):
Could not find OpenSSL. Install an OpenSSL development package or
configure CMake with -DCMAKE_USE_OPENSSL=OFF to build without OpenSSL.请安装上面的libssl-dev 。

vscode均可正常安装上面的插件,如果是trae或者cursor安装插件可以看这篇博客。请注意,在vscode中安装插件只是能让vscode嗅探到对应的环境并且接受数据,不代表ubunt安装了cmake而ubuntu里就有了cmake,该安装还是要安装的。
根据cuda的文档显示,如果window连接wsl使用debug,需要在注册表中进行配置,在:
HKEY_LOCAL_MACHINE\SOFTWARE\NVIDIA Corporation\中新加一个GPUDebugger 项,然后加入一个EnableInterface的(DWORD) ,将其配置为1。
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "CUDA C++: Launch",
"type": "cuda-gdb",
"request": "launch",
"program": "/home/moyu/cuda_study/build/hello"
}
]
}注意,这里的program配置成可执行文件的目录,也就是刚刚./hello运行的文件
{
"files.associations": {
"iostream": "cpp"
},
"cmake.debugConfig": {
"miDebuggerPath": "/usr/local/cuda-12.9/bin/cuda-gdb",
},
"cmake.sourceDirectory": "/home/moyu/cuda_study/course1"
}这里的cuda-gdb目录可以用 whereis cuda-gdb来找到
cmake_minimum_required(VERSION 3.17.0)
project(testdebug VERSION 0.1.0 LANGUAGES CUDA CXX C)
find_package(CUDAToolkit)
set(CMAKE_CUDA_STANDARD 11)
add_executable(hello hello.cu)
target_link_libraries(hello PRIVATE CUDA::cudart ${CUDA_cublas_LIBARAY})
if(CMAKE_BUILD_TYPE STREQUAL "Debug")
target_compile_options(hello PRIVATE $<$<COMPILE_LANGUAGE:CUDA>:-G>)
endif()注意,这里的add_executable要指向文件,请务必留意名字
摁下F5,开始调试,如果右下角出现CUDA的Grid编号,即为成功
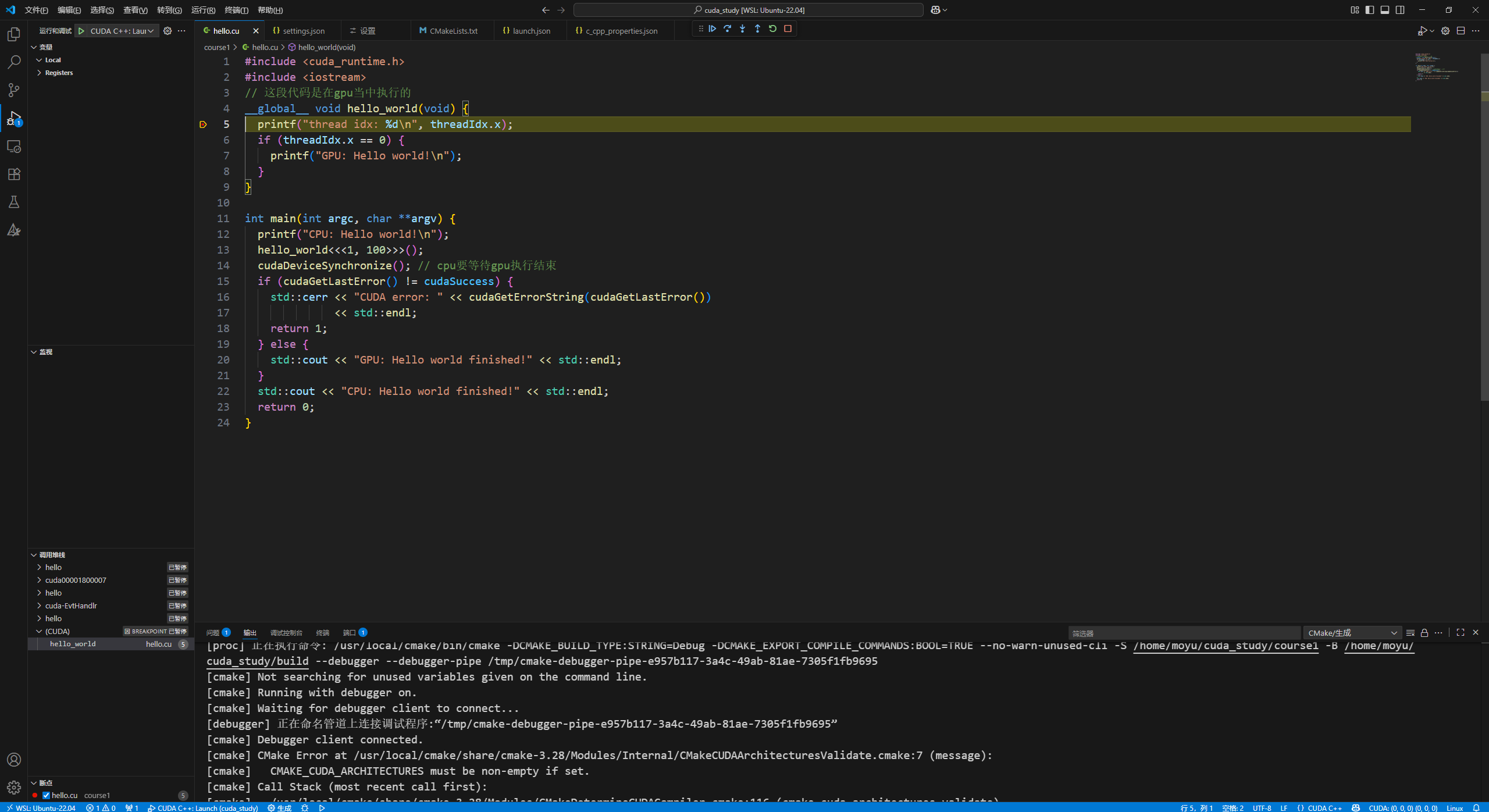
不断的点击单步执行F11,右下角的CUDA Grid就会如下:
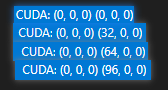
再运行就跳出kernel,此时调试正常。
首先要打开window的GPU性能计数器,注意这里提示说要window管理员,如果不行请回头看看是不是这一步的问题。
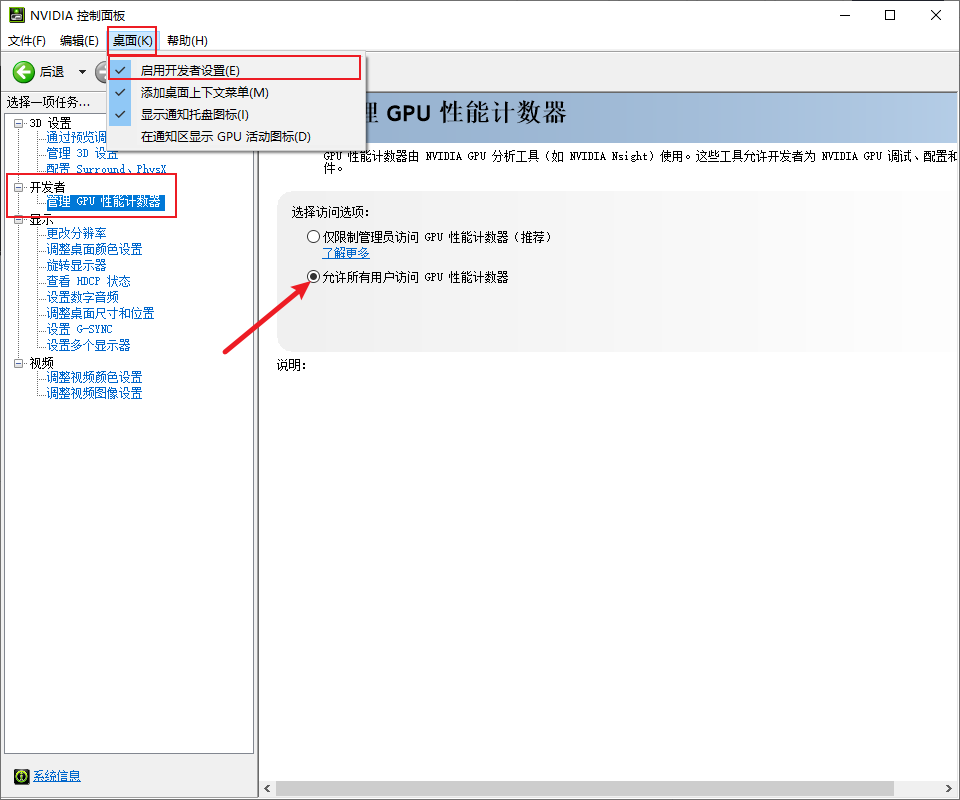
开启之后就可以使用ncu去profiling了。
需要注意的是,下载nsight Computer如果下载最新的版本可能会出现bug,如果出现了奇奇怪怪的bug就不要下载最新的版本,回退一两个版本就行。
这里我们在window安装Nsight computer,地址在这。我这里是突然发现Nsight自动变成了WSL2版本,也不知道为什么。
点开,按照下图进行配置:
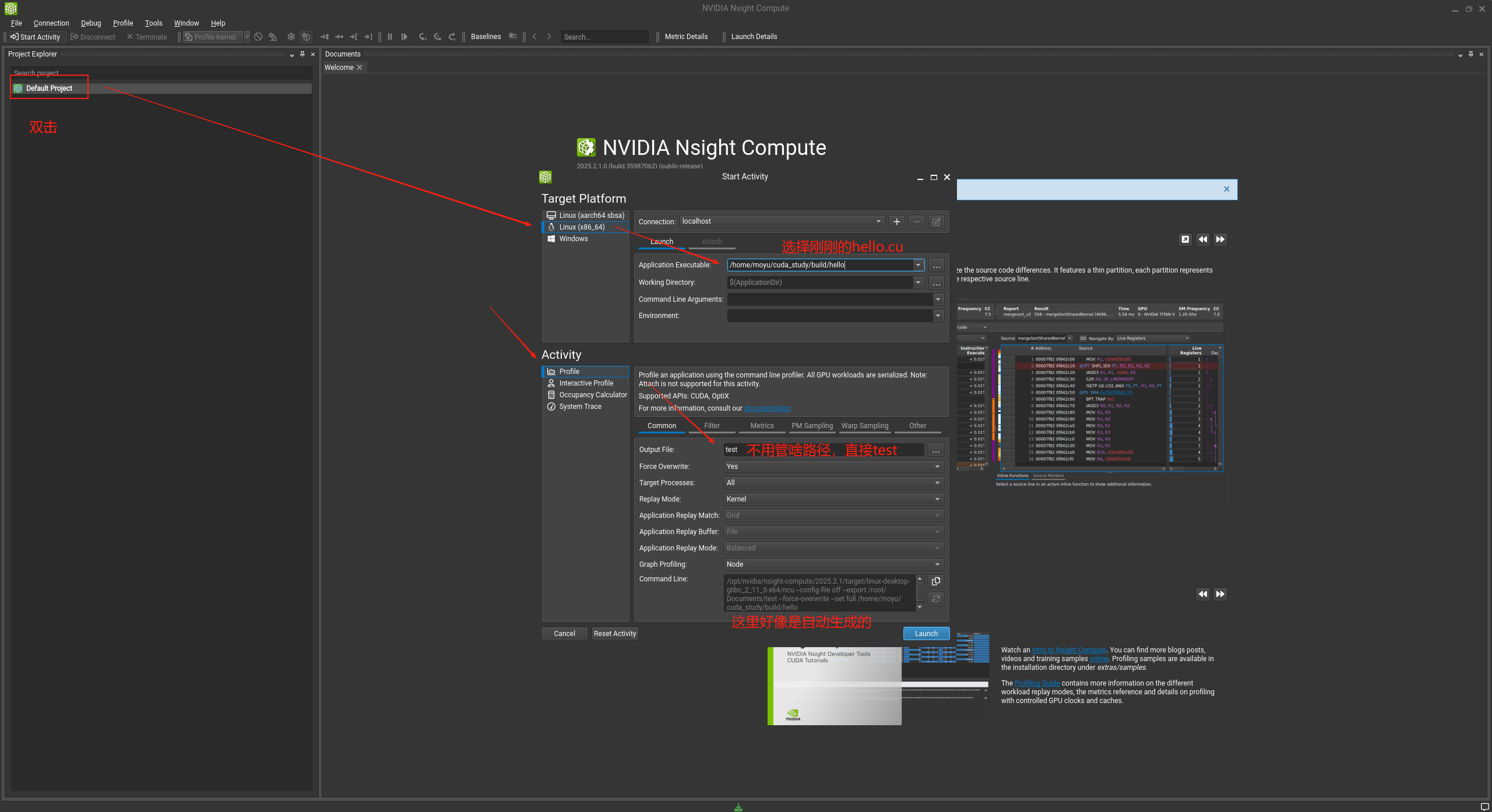
然后将下面的full勾选上,不然分析少了点东西。
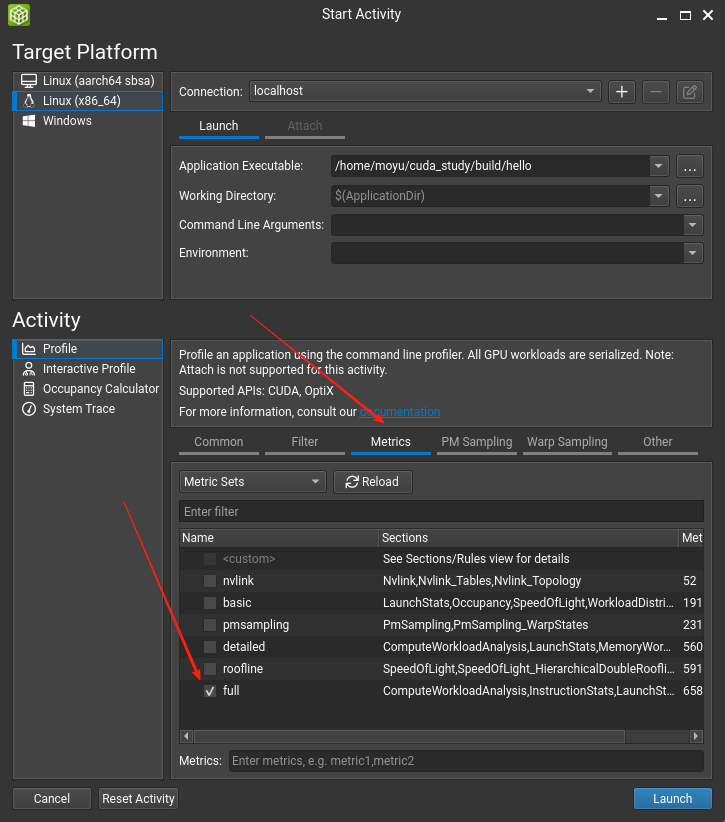
然后点击launch开始分析。
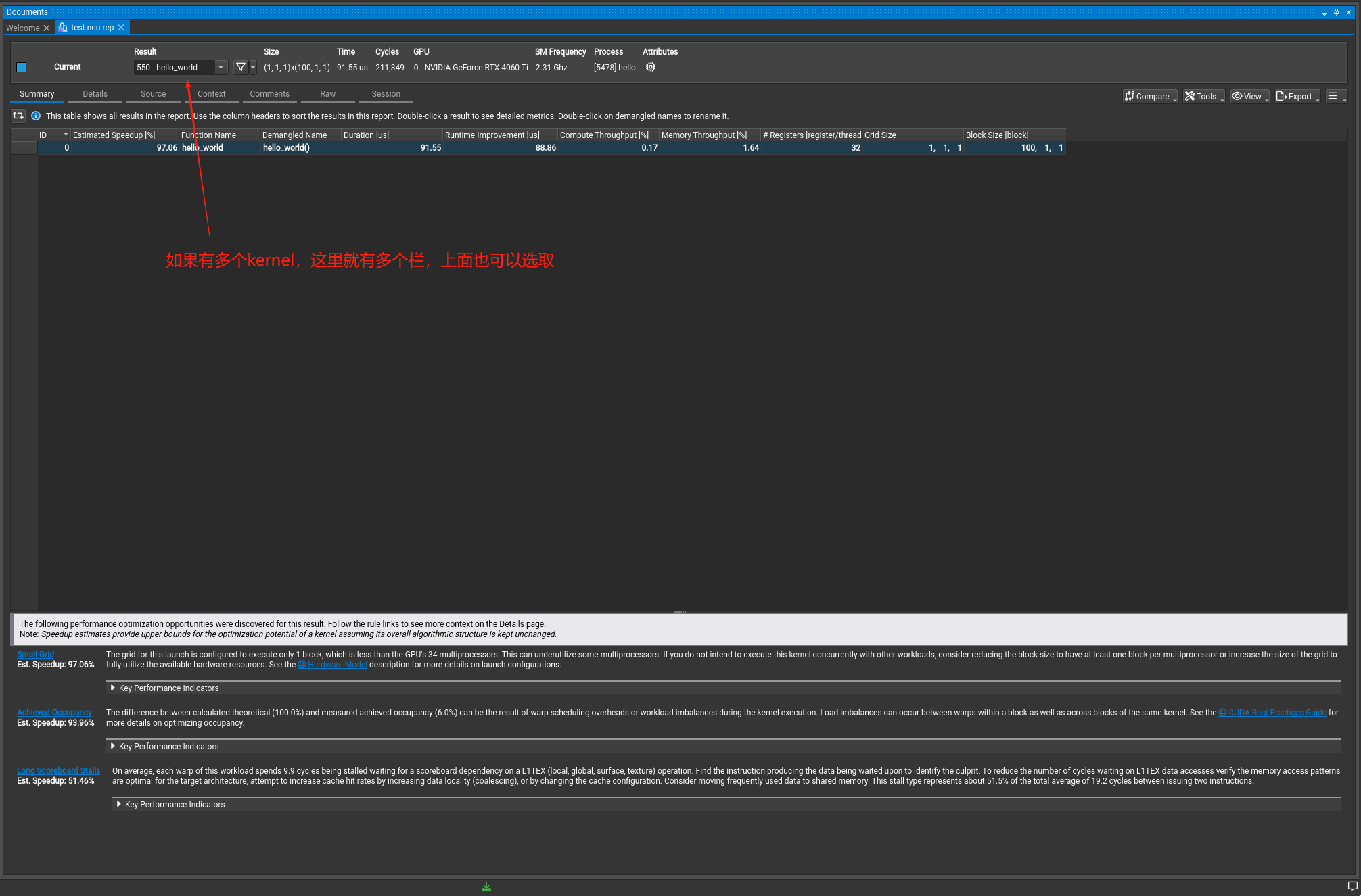
大伙可以随便看看,这里我们可以查看一个点,如下图:
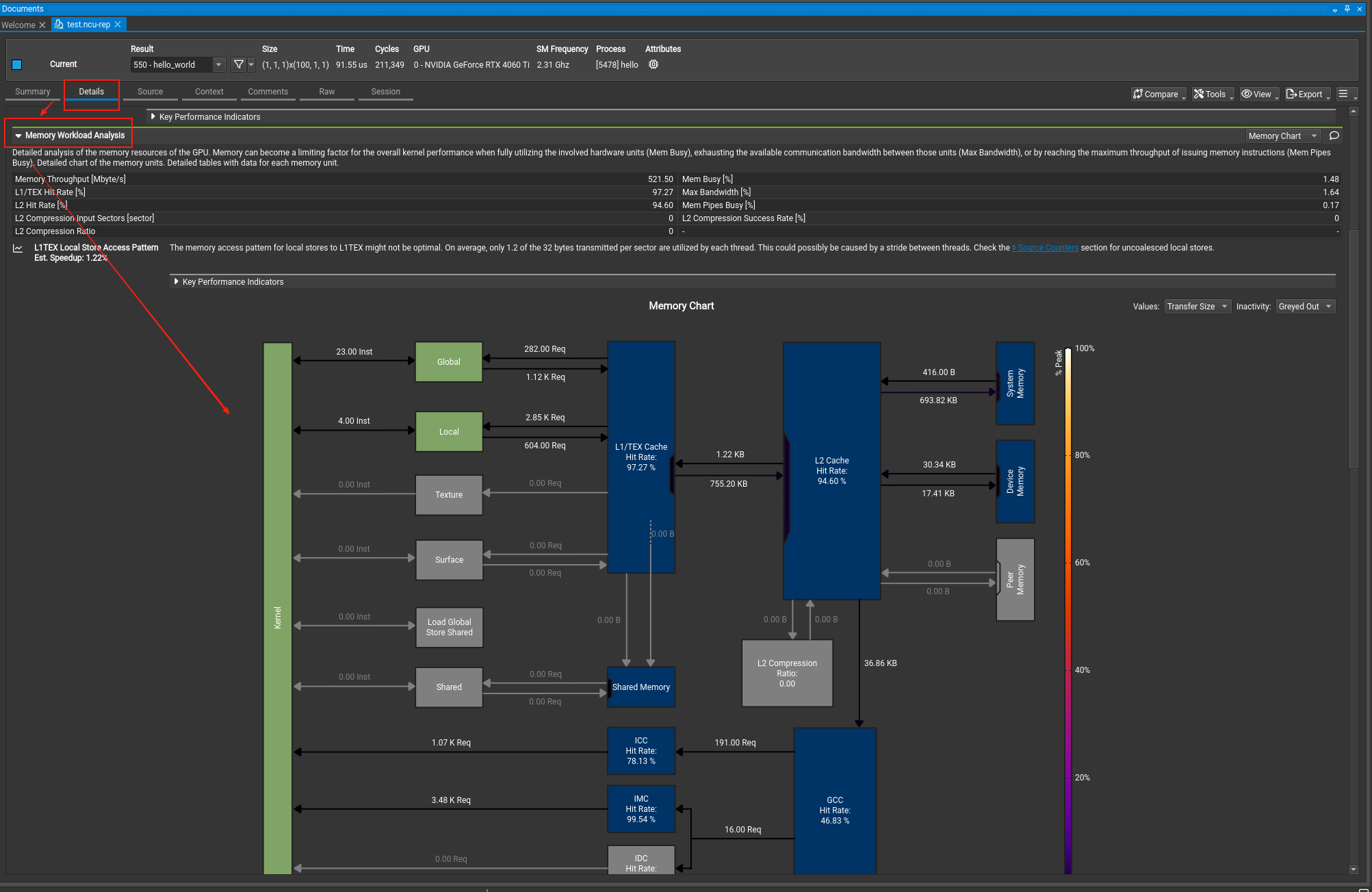
如果没有勾选刚刚的full,那么这里的流程图就不会出现,详情请看文档。
这里我们会谈到一些指标,可能有些超过目前的认知,可以先看看。
(🚧施工ing)
如果你执行了kernel中带有share memory优化的kernel,那么在Nsight computer里对应下图操作:
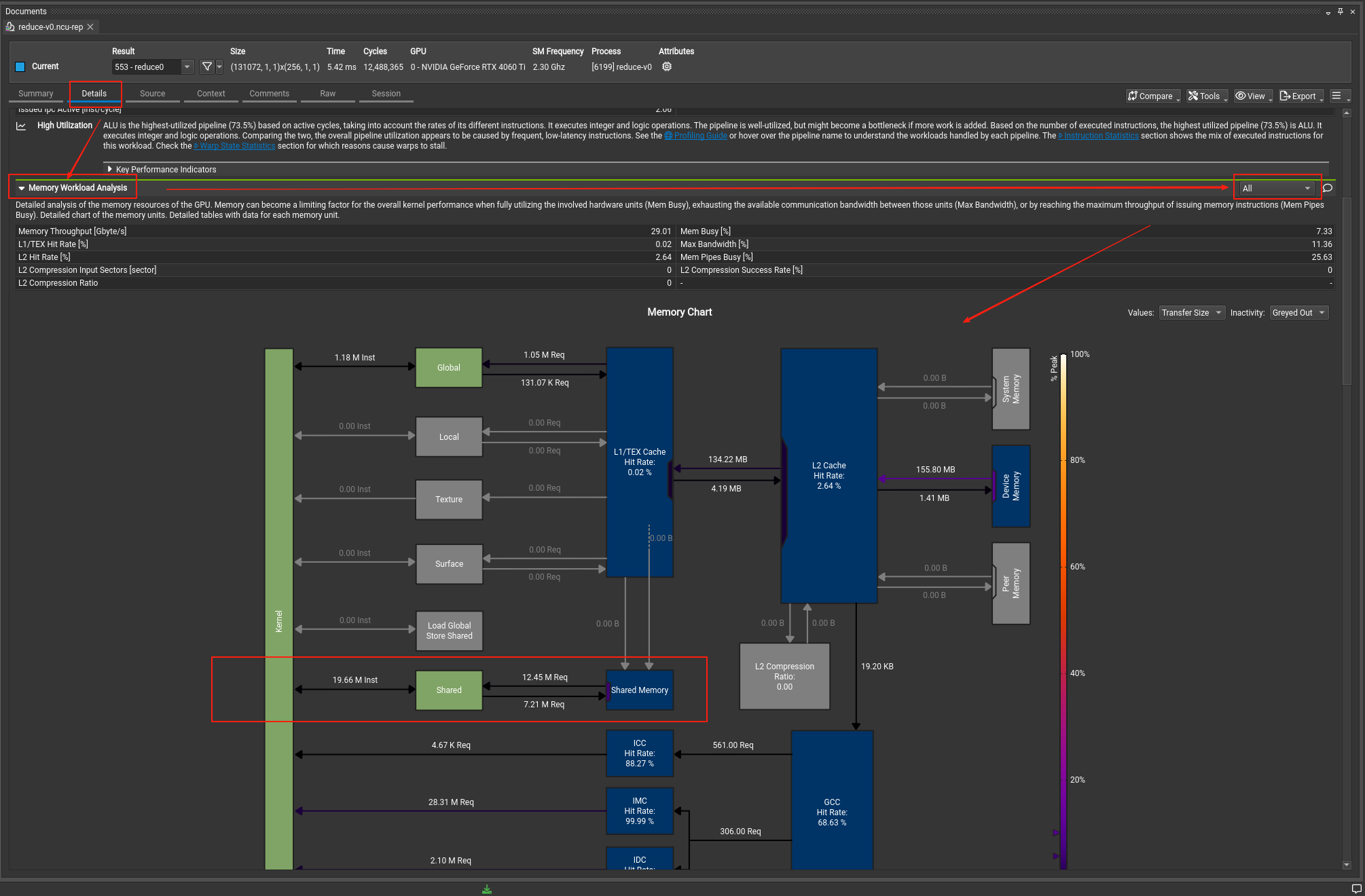
可以看到kernel发射多少条指令,发送了多少请求指令。
继续往下滑就可以看到表格了,如果不选all,就看不到下面的表格数据:
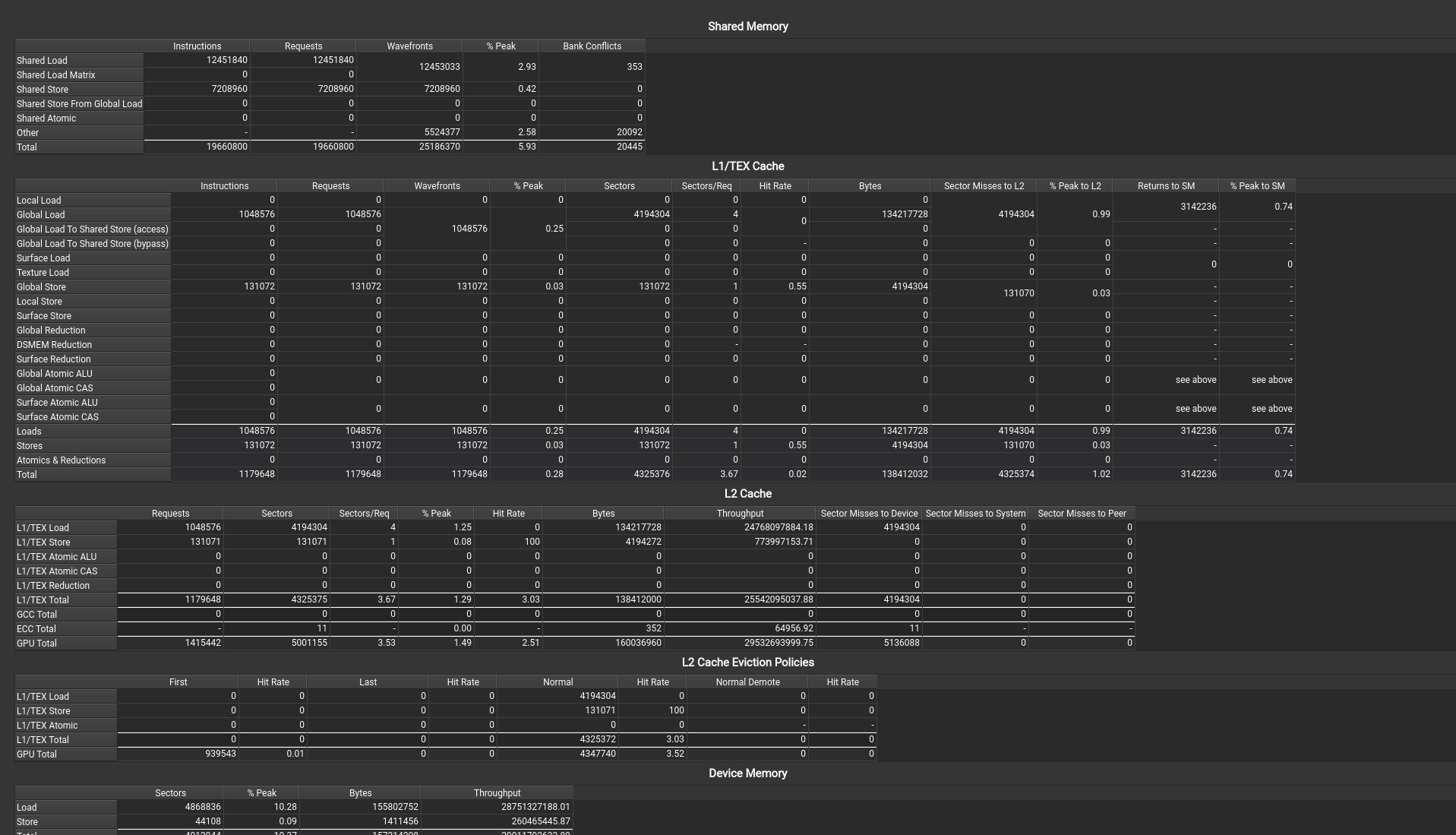
在第一个表的最后一列可以直接看到有多少Bank Conficts内存块冲突,优化的时候就要尽可能的减少它。
每个cuda代码,基本上都遵从一个基本的框架:
把数据从cpu丢到GPU
从GPU安排流水线计算
把结果从GPU拷贝出来
释放内存
这里难点就是在GPU中安排流水线作业,在多卡环境中,我们定义cpu为host,而GPU为device,而在【CUDA从入门到入土】一、丝滑的CUDA入门中,我们看到了一个kernel为:
#include <cuda_runtime.h>
#include <iostream>
// 这段代码是在gpu当中执行的
__global__ void hello_world(void) {
printf("thread idx: %d\n", threadIdx.x);
if (threadIdx.x == 0) {
printf("GPU: Hello world!\n");
}
}
int main(int argc, char **argv) {
printf("CPU: Hello world!\n");
hello_world<<<1, 10>>>();
cudaDeviceSynchronize(); // cpu要等待gpu执行结束
if (cudaGetLastError() != cudaSuccess) {
std::cerr << "CUDA error: " << cudaGetErrorString(cudaGetLastError())
<< std::endl;
return 1;
} else {
std::cout << "GPU: Hello world finished!" << std::endl;
}
std::cout << "CPU: Hello world finished!" << std::endl;
return 0;
}其中的__global__ 表示只能从主机端调用,在设备端执行,返回值是void的一个核函数。
而这样的kernel到底是面向block还是thread的呢?
在【CUDA从入门到入土】一、丝滑的CUDA入门中,我们已经知道GridDim是用来定义block摆放的样子,而blockDim是用来表示一个block最多有多少个thread,而threadIdx是表示当前是第几个thread。那么一个__global__ 的kernel function是先索引某个threadIdx 的,那肯定是面向thread来编程啦,毕竟thread才是最小的单位,代码里输出的也是threadIdx。
kernel编程的是面向thread的。。。。。。。吗?
显然,不完全对,因为block和thread被我们下意识的分开了,但其实他们俩是不能分开来讨论的,block和thread存在的意义,都是为了更好的并发执行运算,他们俩在编写并发程序时,并发优化的方法已经从单一thread优化到了warp,到了block,甚至到了Grid,所以从一开始,我们就不应该割裂开这三个,通过下图我们更能体会其中的含义:

所以本质上,Grid、block和thread只是划分数据进行并行的不同单位,通过层级嵌套管理进行分配。
所以当我们拿到一个新的问题的时候,我们要对数据进行划分,由于cuda的kernel function是面向block的,那么我们画图的时候只需要关注一个block关注的数据,然后写代码的时候由于我们是写一个thread如何并行,那么kernel里是要写thread的code,这点我们在后面会反复提到。
在第一章的时候,我们提到过一个SM的内有多个Warp scheduler,这里涉及到一个问题,我们设计kernel的时候thread的数量和block的数量关系应该如何呢?
现在已知的条件是一个warp会并发32个thread,根据H100内有4个warp scheduler,也就是能同时并发128个threads。在讨论数量关系的时候,最好就是讨论特殊关系,然后再将特殊关系一般化。
假如说kernel内我设置每个block的threads就是128,跟block每次并发的个数一样,那会发生什么呢?我们来思考一下这个过程,block内每个thread执行kernel function,从global memory拿数据,放到shared memory,执行运算,把数据写会global memory或者寄存器。这一切都很正常。。。。。吗?
这里我们要谈到cuda一个核心且最重要的宗旨,就是要拉满GPU和利用率,当block内thread执行kernel的时候,需要从global memory取数据放到shared memory,这里存在了一个访存的气泡,而访存的时间和高速并发运算的时间并不是一个维度的概念。
(这里可以设计试验进行验证)
所以我们要拉大block内threads的数量,最好在四倍以上,这样能保证访存期间SM内一直都有运算指令运行在访存期间,这样就可以拉满GPU利用率。
