这篇文章记录我熟悉的codex和claude code的常用方式,若有更好的方法欢迎联系我。
其实无论是在哪个终端安装都可以,无非是权限的问题,在wsl或者git bash中是最好的,但是我习惯在Window的terminal安装了,直接安装即可,问题不大。
npm i -g @openai/codex
npm install -g @anthropic-ai/claude-code
irm https://claude.ai/install.ps1 | iex # 官方用的是这个然后就是源配置,这里很多教程会教怎么配置json,怎么改之类的,这里选择最简单的方法:cc-switch
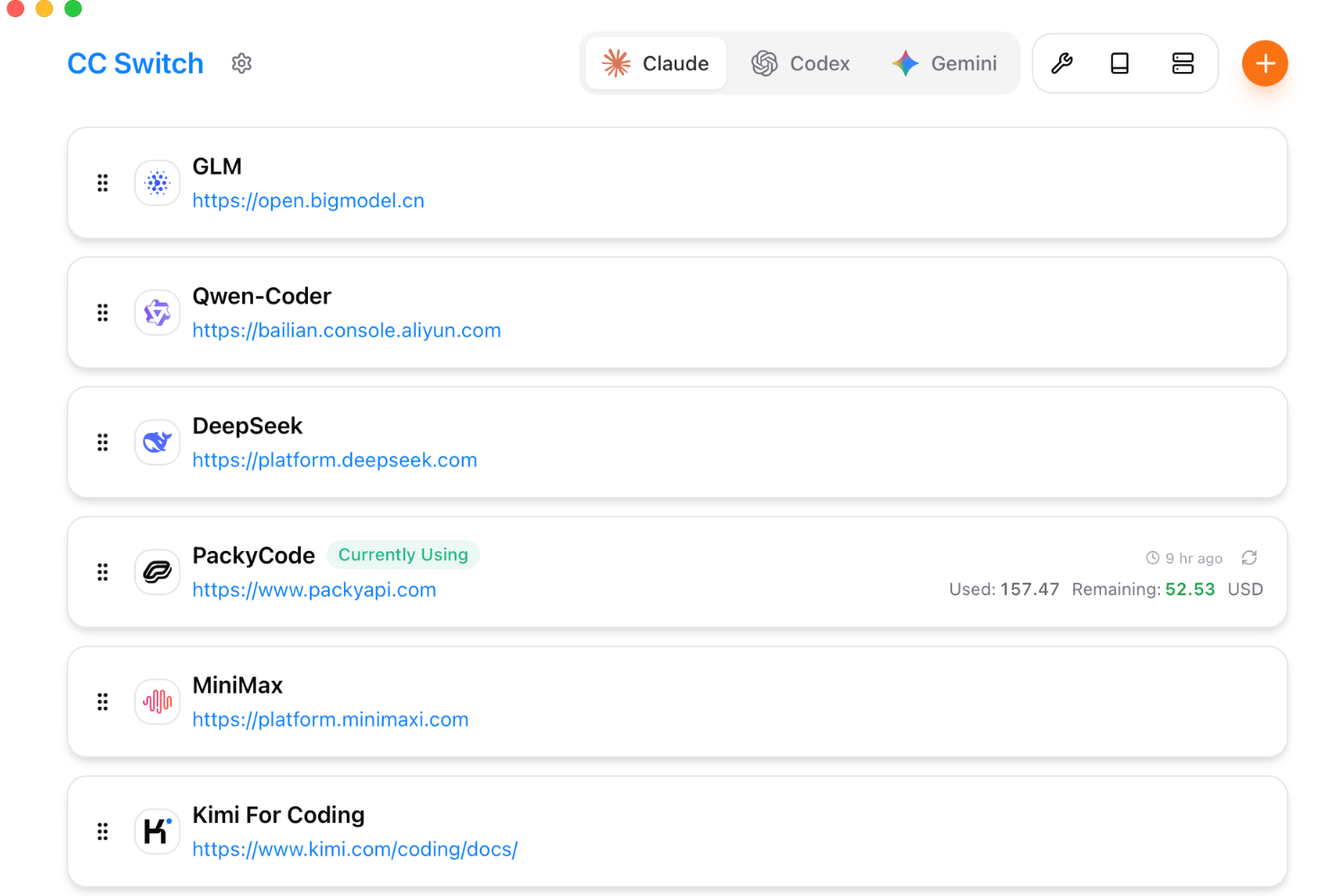
这里可以根据不同的cli配置不同的源,非常方便,如果使用中转网站,只需要把要用的模型名字 + api服务地址 + api设定好就行,具体每个中转网站不一样,可以进行详细的配置捏,这里我们以yunwu中转网站为例。在中转网站中小氪一手,然后选择api令牌进行配置:
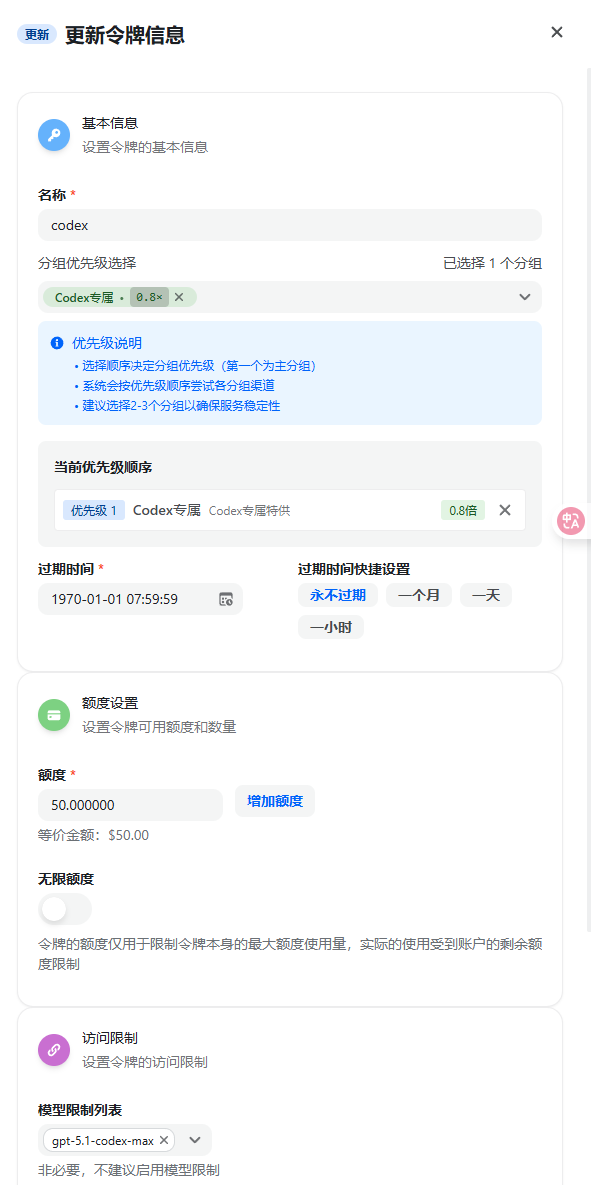
具体的倍率或者名字之类的,可以在左上角模型广场中看到,claude会贵一点,codex会便宜一点,其实不必要用最好的,就选上一代降价了好模型就行。配置完了之后,打开cc-switch,进行配置:
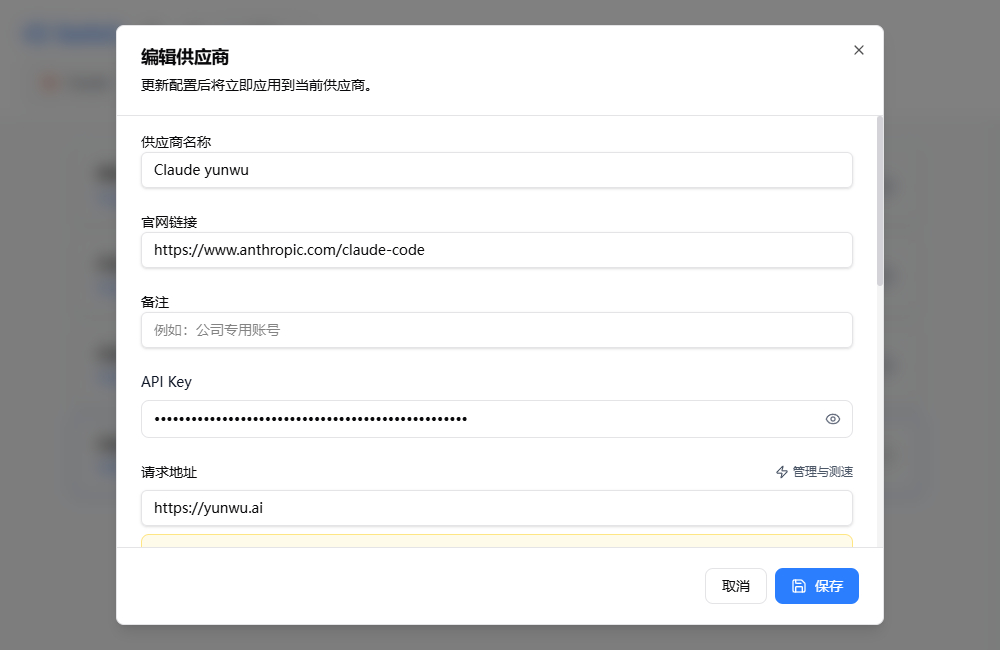
我这里配置的是claude,官网链接可以不理,下面还有一个模型的名称,进入yunwu的控制台,在个人设置里可以复制模型的名字,填进去就行。打开terminal,输入claude或者codex,/model就可以查看对应的模型了。
不得不说国产确实🐂,态度好,模型不赖,也便宜,这里推荐GLM捏~
打开coding plan,先买一个月的,很便宜,然后去右上角找到api key注册入口,注册一个api key。
由于CC switch跟GLM关系好,所以已经内置了选项了,直接选好了丢个key进去就行
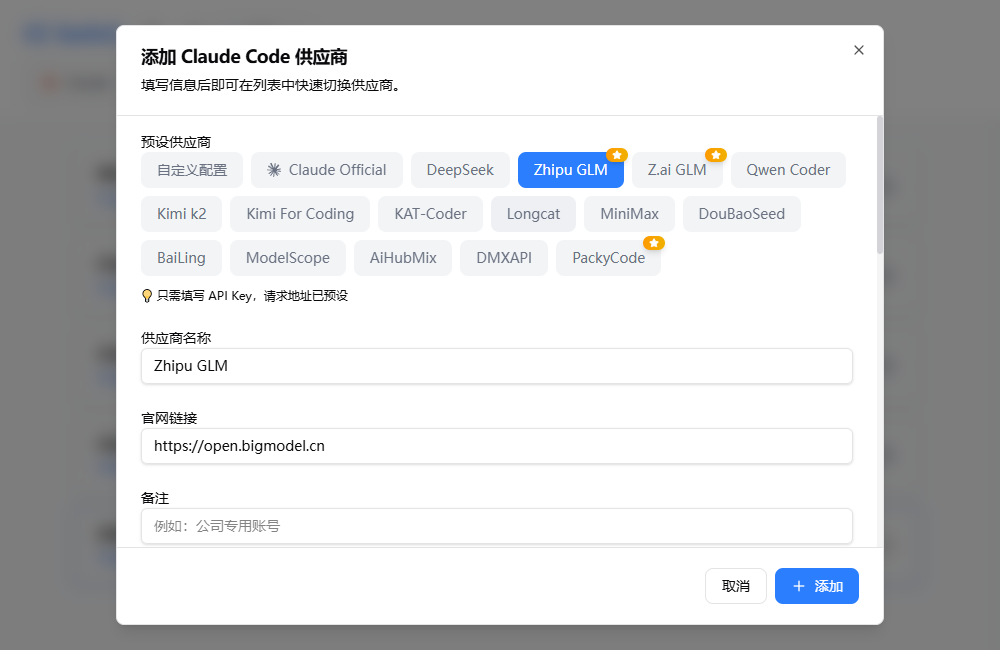
然后是配置联网搜索和网页读取,可以看下面的,也可以读读doc,可能时过境迁,技术迭代之后有变化:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "your api",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_MODEL": "glm-4.7"
},
"mcpServers": {
"web-reader": {
"headers": {
"Authorization": "your api"
},
"type": "http",
"url": "https://open.bigmodel.cn/api/mcp/web_reader/mcp"
},
"web-search-prime": {
"headers": {
"Authorization": "your api"
},
"type": "http",
"url": "https://open.bigmodel.cn/api/mcp/web_search_prime/mcp"
}
}
}这里记得替换你的api哟
首先是换行,得切换到终端模式才行,不然shift + enter只会发送:
/terminal-setup开启之后会根据它疑惑的颗粒度进行提问,很像deep research,非常好用:
开启方式:
# 基础 Plan 模式
claude --permission-mode plan
Mac 系统:Shift + Tab ×2
Windows 系统:Alt + M 或 Shift + Tab ×2如果对话框冒出来: ⏸ plan mode on (alt+m to cycle) 就证明开启成功
claude --dangerously-skip-permissions
Shift + Tab ×2 # 在复杂问题前添加关键词
"think harder: 如何设计高并发短链服务?"
"ultrathink: 请详细分析这个算法的复杂度"首次使用时执行 claude init 自动生成 CLAUDE.md,存储:
项目架构说明
代码规范偏好
常用命令别名
无需 # 指令,直接告诉 Claude"请更新 CLAUDE.md"即可
# 在 tmux 会话中
Ctrl+b c # 创建新窗口
cd ~/project-a
claude
# 切换回第一个窗口
Ctrl+b 0
cd ~/project-b
claude需要注意的是,claude不冲突的起点是工作目录不一样,工作目录一样可能会有冲突的。
Esc 中断当前操作
双击 Esc 回到上一个对话节点
@文件名 精准引用文件
#内容 记忆到 CLAUDE.md
Ctrl + _ 撤销操作:类似 Vim 的撤销
Ctrl + V 粘贴图片
/clear # 清空当前会话上下文(保留 CLAUDE.md),比 /compact 更高效
/compact # 压缩长对话,节省 Token,适合会话过长时续接
/resume # 查看所有历史对话列表,输入数字快速续接
/model # 切换模型(Sonnet/Opus/Opus Plan 模式)
/cost # 查看当前会话的 Token 消耗统计
/export # 导出对话记录为文件
/terminal-setup # 配置终端支持 Shift+Enter 换行
/config # 查看当前配置由于我们常在各种ide里使用cc,个人习惯在vscode开cmd,但是有时候cmd要魔法一下,但是我又懒得每次输入那两条命令,那就在创建窗口时自动执行,首先新建一个cmd_init.txt ,在其中输入:
set http_proxy=http://127.0.0.1:7897
set https_proxy=http://127.0.0.1:7897记得用自己的端口号,然后保存成cmd_init.cmd 。
管理员身份打开注册表,在计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Command Processor 中新建一个字符串值,输入刚刚保存的地址,比如说我是:
D:\something\cmd_init.cmd保存之后,新建一个terminal,默认就会执行那两行命令。
通常我们可能并行有几个上下文需要管理,那么就会存在一个场景就是我突然想问一个另外的问题,但是不行污染这个上下文,应该怎么办呢?首先是查看历史,进去之后就可以看到历史会话,回车就进去了:
claude --resume那如何把一个上下文保存到第二个上下文呢?只能说把第一个上下文进行总结成markdown,然后让第二个上下文去读,只有这种了。
那如何把上下文提取出来呢?这就要说到上下文的保存方式了,window系统一般都保存在这个目录下:
C:\Users\用户名\.claude\projects所有会话都在里面,如果要进一步管理,可以使用:
# 安装会话提取工具(可选)
pipx install claude-conversation-extractor
# 导出为 Markdown
claude-extract --format markdown --all首先我们要建立一个非常简单的认知,现在大模型存在的问题如下:
大模型的上下文窗口并不长,我们一次喂给它的内容是有限的,所以要使用分治思想,让它一块一块的处理。
大模型知道的东西非常多,我们需要给它一个清晰的范围,构建明确的输入输出边界。
大模型对业务的实现方案有非常多种,技术选型不一定要选最优秀的,要选最合适的。
由此可见,什么几行字让ai生成一个完美的软件,在现实中是不切实际的。在传统开发中,"想法"到"产品"的路径是:想法 → 需求文档 → 设计稿 → 代码 → 测试 → 上线。每一步都需要专业人员,每一步都可能出现理解偏差。
在 AI 时代,这条路径被大幅压缩:想法 → 结构化描述 → AI 生成代码 → 人工验收 → 迭代优化。因此,我们必须要先构建好自己的想法,通过结构化的描述,限定好范围,再去让ai生成对应内容。
那么如何让terminal的cc或者codex写文档呢?当然是让它生成一个markdown,后续所有内容续写即可。
首先的首先,一定一定要清楚场景和需求,也就是构建PRD。在ai中,已经有多agent的专家模式去开发写代码了,所以ai生成一份代码,在后台通常已经走过了一轮agent,这时候我们就要清晰的表达自己的需求,这通常不会很复杂,就是一步一步的构建而已。
那么如何从0开始构建一份ai看得懂的需求文档呢,我认为针对于每一个功能,需要用户输入以下几个部分:
明确对象和对象的功能
与别的组件之间的交互
few shot examples
最后补一句:“你觉得这个功能可能存在的各方面风险有什么,请给出五条质疑”
通过用户写出这三个部分的input,让ai生成专业的PRD描述,然后人为的去检验即可,如果没想到足够好的few shot example,那可以让ai生成,然后我们去思考逻辑即可。最后通过修补质疑,来让ai生成更为详细描述的PRD。
当你完成了所有功能的描述,必然最开始的功能会膨胀或者乱了一些,这时候你就要让ai进行总结,把这个markdown总结成一个成熟的项目,有成熟的项目目标,具体的功能划分等等。这里的prompt要根据你的项目来,最核心的是要总结出该项目最核心的几条workflow的功能需求。后续的所有技术展开都是根据这几条workflow来的。
通过对需求文档的构建,我们对功能的划分已经结束了,这时候要做的就是写技术文档,通常最难的一点就是对整体技术的把控,这时候就需要用到上面提到的几条workflow了,需求文档通常来说会又臭又长,把整个上下文空间填满了,但是总结过的workflow就很清爽的表达了核心的要点和限制条件。那么有输入了,如何构建技术文档的输出呢?
首先是敲定整体的系统架构,通过分层设计,把每个业务锁定在层里,这里要遵循的就是一个哲学思想:抽象和自动化。简单来说,这里可以分为四层:
上面是传统的四层架构,当然现在hpc的技术下的数据密集型系统分层包括:
采集层:日志埋点、CDC、Kafka,负责数据接入
存储层:HDFS、S3、OSS,负责低成本持久化
加速层:Flink、Spark Streaming,负责低延迟计算(处理近期数据)
批处理层:Spark SQL、Hive,负责全量计算(生成历史物化视图)
服务层:HBase、ClickHouse、API,负责高吞吐查询
采集层给存储层提供数据持久化,存储层给加速层提供流式计算和增量计算服务,加速层给批处理层提供数据合并、物化视图等服务,批处理层给服务层提供curd之类的功能。
需要注意的是:
避免贫血模型:领域层只存数据无行为,逻辑泄漏到应用层
避免循环依赖:应用层和服务层互相调用,通过事件总线解耦
避免跨层事务:分布式场景下,用Saga模式替代ACID事务
避免过度分层:简单CRUD系统用三层架构即可,DDD增加复杂度
那么对于技术栈,这里要做的就是横向拉个表格,然后选择自己需要库。先单个技术栈分析,选择自己需要的,然后把技术栈进行交叉分析,分析针对业务的可行性,可行性验证完毕即可开始分层。那么如何分析呢,主要有以下指标:
数据规模:读写的速率和存储的规模
并发量级:单体?上云?
延迟敏感度:单体?上云?Redis?K8S?
技术选型不一定要选最新的,最合适的就是最好的,构建技术栈的时候,要从底向上的进行构建。层与层之间必须设定好接口。必须要留下监控性能指标的api接口。
这时候只需要ai去work,prompt就是根据需求文档的前面的总结 + 一个一个的需求,在技术文档中找到对应的内容,进行代码生成。
当然有很多别的skill,比如说代码生成的风格,如awesome-cursorrules。当你对agent或者context engine的优化技术懂的足够多,你会在这篇博客中找到影子,后续会继续优化它。
当然你可能会说,哎这个太复杂了,我就写一点小功能,至于吗?
我的回答是至于。如果要搓demo,那简单的需求文档就能解决了,但是这种demo复用非常困难,容易报错,我的建议就是当你开始coding,就养成好习惯,从文档开始,后续的每一步都有锚点,这非常重要。
参考文档:
