新模型
新module出现,需要对应算子进行计算,还需要结合硬件进行特性优化和测试,尽量充分发挥硬件性能
硬件厂商还会发布新技术的加速计算库
专用加速芯片爆发导致性能可移植性成为一种刚需
不同厂商的ISA不尽相同
一般缺乏如GCC、LLVM等编译工具链,使得针对CPU和GPU已有的优化算子库和针对语言的优化Pass很难短期移植到NPU上

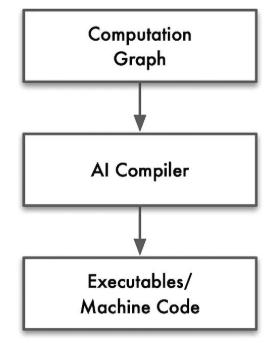
在编译优化层通过统一IR执行不同的Pass进行优化,从而提高执行性能
软件结构栈:分成前端、优化、后端三段式,IR解耦前端和后端使得模块化表示
AI编译器对Graph IR进行优化后,将优化后的IR转换成传统编译器IR,最后依赖传统编译器进行机器码生成

左边是旧编译器架构,右边是ai编译器架构
IR差异
由于LLM模块化重复度很高,所以有了AI编译器一般会有high-level IR,AI编译器在描述深度学习模型类DSL更加方便
high-level IR用来抽象描述深度学习模型中的运算,如:Convolution、Matmul等,甚至部分会有Transformer带有图的结构
AI编译器在high-level IR执行算子融合
AI编译器可以降低计算精度,比如int8、fp16、bf16等,因为深度学习对计算精度不那么敏感。但传统编译器一般不执行改变变量类型和精度等优化

AI编译器一般采用多层级IR设计。 下图展示了TensorFlow利用MLIR实现多层IR设计的例子(被称为TensorFlow-MLIR)。其包含了三个层次的IR,即TensorFlow Graph IR, XLA(Accelerated Linear Algebra,加速线性代数)、HLO(High Level Operations,高级运算)以及特定硬件的LLVM IR 或者TPU IR,下面就不同的层级IR和其上的编译优化做一个简要介绍。

多层级IR的优势是IR表达上更加地灵活,可以在不同层级的IR上进行合适的PASS优化,更加便捷和高效。 但是多层级IR也存在一些劣势。首先,多层级IR需要进行不同IR之间的转换,而IR转换要做到完全兼容是非常困难的,工程工作量很大,还可能带来信息的损失。上一层IR优化掉某些信息之后,下一层需要考虑其影响,因此IR转换对优化执行的顺序有着更强的约束。其次,多层级IR有些优化既可以在上一层IR进行,也可以在下一层IR进行,让框架开发者很难选择。最后,不同层级IR定义的算子粒度大小不同,可能会给精度带来一定的影响。为了解决这一问题,机器学习框架如MindSpore采用统一的IR设计(MindIR)。

参考文献:
